
【更新中】一本书教你通关计组实验(下)
目录
第四章:单周期 CPU
4.1 现在可以公开的情报:一些前置知识
4.2 使用 Logisim 模拟单周期 CPU
4.3 使用 Verilog 模拟单周期 CPU
4.4 本章结语:再见,单周期 CPU !
第五章:五级流水线 CPU
5.1 现在可以公开的情报:一些新的前置知识
5.2 五级流水线 CPU 的基本构造
5.3 阻塞与转发
5.4 使用 Verilog 模拟五级流水线 CPU
5.5 五级流水线 CPU 实战:加指令练习
5.6 五级流水线 CPU 大升级:新指令与新模块
5.7 本章结语:再见,五级流水线 CPU ?
终章:带中断异常的五级流水线 CPU
Final.1 现在可以公开的情报:最后的前置知识
Final.2 CP0 模块的结构与功能
Final.3 中断异常全流程
Final.4 外部设备模拟
Final.5 本章结语:再见,五级流水线 CPU !
第四章:单周期 CPU
4.1 现在可以公开的情报:一些前置知识
终于!我们已经集齐了 Logisim 、Verilog 、MIPS 三大神器,准备开始我们漫长的 CPU 征途了!在我们正式开始之前,我们需要了解一些在上本书中没有学到的前置知识,也算是我们踏上征途前的最后准备吧!
【CPU】
不会有人已经快要动手搭 CPU 了,还不知道什么是 CPU 吧?(笑)没关系,我们赶紧了解一下,现在还来得及!
我们知道,我们编写的 C 语言程序要想能够运行,需要通过编译转换为汇编语言,再将汇编语言转换为机器码,这些流程 —— 都不是 CPU 的工作…… CPU 真正的工作是,将已经全部处理好的机器码作为输入,执行其中的汇编程序,达到修改寄存器和内存中的值的效果。这也正是我们要实现的内容。
事实上,我们一直在使用的 MARS 就是在模拟这个过程。我们在其中编写汇编程序,交给 MARS 来运行,就能够观察到寄存器和内存中发生的变化。在接下来的学习中,我们完全可以参照 MARS 执行指令的流程,从而能够更好地理解 CPU 的运行机制。当你在以后对 CPU 的运行逻辑产生困惑时,不妨回头看一下 MARS 是如何实现这个过程的,相信会对你有所帮助!
【空指令nop】
接下来,我们来认识一条特殊的指令 —— nop 。nop 指令的机器码是 0x00000000 ,一看就非常不简单。它的作用就是没有任何作用,如果我们查询每条指令的机器码,就会发现 nop 指令实际上等价于 sll $0, $0, 0 指令,确实没有任何作用。
那么你肯定会问,我们为什么需要一条没有任何作用的指令呢?我们先按下不表,到五级流水线 CPU 一章,你或许会再感受到它的存在的。
4.2 使用 Logisim 模拟单周期 CPU
接下来,我们就要正式开始搭建 CPU 了!我们本章的旅程主要分为两个部分:在本节,我们将要认识单周期 CPU 的全部架构,并使用 Logisim 完成一个属于自己的单周期 CPU ,实现 14 条 MIPS 指令:nop addu subu addiu xori lui lw sw beq bne j jal jr jalr ;在下节,我们将要将我们的单周期 CPU 移植到 Verilog 语言,实现两个版本的单周期 CPU。
在正式开始之前,还是要温馨提示一下,虽然本书已经给出了全部的实现细节,但还是希望你能够在看完每节,彻底了解了实现思路之后,挑战在不看本书的情况下自行完成 CPU ,毕竟你也不想查重被抓到小黑屋里接受审判吧只有这样才有自己独立完成一个大工程的成就感嘛!(笑)
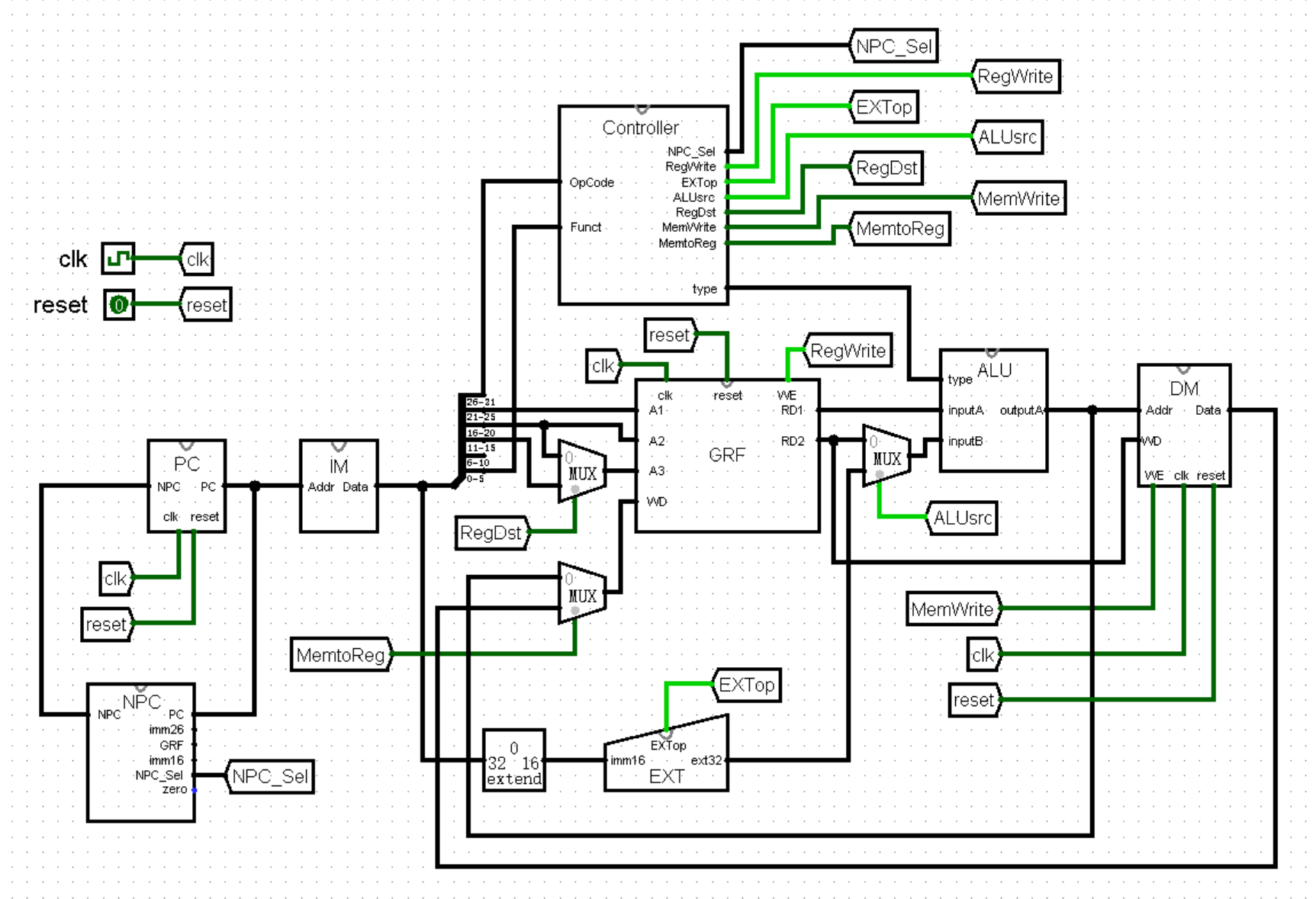
【CPU中的存储模块:PC、IM、GRF、DM】
在上一节我们已经知道,CPU 要实现的目标就是正确修改寄存器和内存这些存储模块中的值,所以搞清楚 CPU 中有哪些存储模块,以及如何确保它们的值时刻正确,就是我们搭建 CPU 的第一要务!
于是,我们就要思考一下,CPU 在执行指令的过程中,都会用到哪些存储模块呢?当然了,从大范围上说,其实就是我们刚才提到的寄存器和内存两种。不过我们也可以将它们两个再细分一下,或许对我们接下来的搭建工作更有帮助。
提到寄存器,我们首先能够想到的肯定就是 $0 到 $31 这 32 个寄存器了,我们将它们称为“寄存器堆”(GRF)。在执行绝大多数指令时,我们都需要从这些寄存器中取出值;同样,在很多情况下,我们也需要将计算的结果写入寄存器中。在后面的部分中,我们也将学习如何搭建这个庞大的 GRF 模块。
不过,在我们的 CPU 中,就只有这 32 个寄存器吗?让我们来仔细回忆一下,还记得有一个叫做 PC 的寄存器吗?它代表着当前正在执行指令的地址。在跳转指令的符号语言描述中,我们曾经用到过这个寄存器,在我们的 CPU 中,我们也会将其独立成一个 PC 模块,用于取指令的寻址。
当然,除了 GRF 和 PC 寄存器之外,我们还有一些独立的寄存器,例如 HI LO 寄存器和我们素未谋面的 CP0 寄存器,这些寄存器在我们后续添加相关模块的时候会讲到,在这里就暂且略过了~
接下来,我们再来研究一下内存这个大类。在 CPU 中,我们同样需要开辟一块存储空间来作为内存,这就是 DM 模块。
不过我们不要忘记了,在 MARS 中,内存实际上是被分为两块区域的:地址为 0x00000000 到 0x00003000 的 .data 段作为自由存取的空间,而地址高于 0x00003000 的 .text 段作为存储指令机器码的空间。
在我们的 CPU 中,为了便于搭建,我们将这两个部分拆成两个模块,我们将存储指令机器码的 .text 段从 DM 模块中分离出来,单独形成一个 IM 模块。这样两个部分的读写互不干扰,解决了很大一部分的冲突问题。
(顺带一提,我们的 CPU 中这种 IM 和 DM 分离的结构被称之为哈佛结构;相反,类似于 MARS 内存中不分离的结构被称之为冯·诺依曼结构或者普林斯顿结构)
到目前为止,我们已经了解了我们这一阶段会用到的所有存储模块。在接下来的工作中,我们要做的就是通过一系列操作实现每一条指令,保证这些存储模块中的值正确无误即可!
【取指令:PC、NPC、IM模块】
如果我们想要让我们的 CPU 要执行一条汇编指令,第一步应该是是什么呢?当然是要正确取出这条指令了!于是,我们就需要搭建一个能够稳定输出当前执行指令的地址的装置 ——
首先,我们使用一个 32 位寄存器作为 PC 寄存器,表示当前指令的地址:
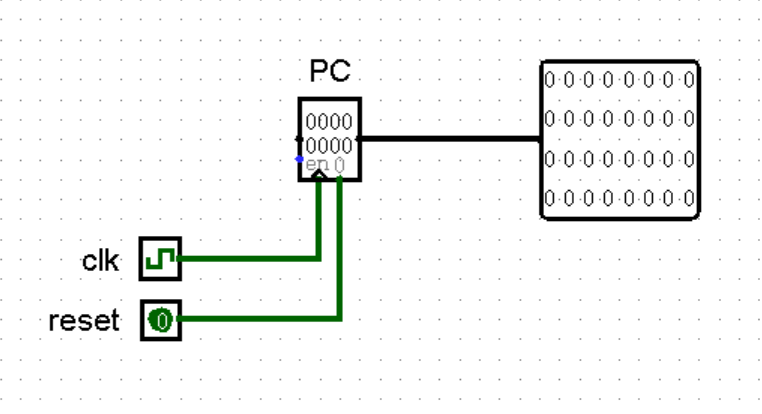
我们知道,每当我们的 CPU 执行完一条指令,切换到下一条指令的时候,PC 寄存器的值都会随之更新到下一条指令的地址。也就是说,每当时钟到达上升沿的时候,我们就需要更新一次 PC 寄存器的值。
以最常见的非跳转指令为例,每当执行到下一条指令时,PC 寄存器的值都会 +4 ,还记得这个知识点吗?这是因为我们的 MIPS 指令都是 32 位,也就是 4 字节的,所以每两条指令之间的地址自然相差 4 。实际上,如果我们把 PC 寄存器的值看作状态机的状态,这就形成了一个非常经典的状态机:
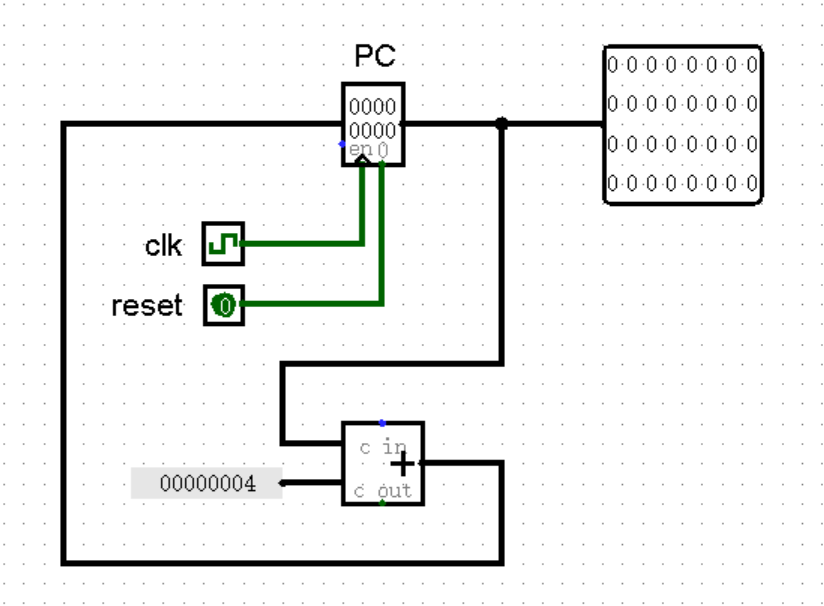
当然了,这个状态机肯定不止现在看上去这么简单。一方面,为了模仿 MARS 中指令在内存中的地址,我们的 CPU 中 PC 寄存器的初始值被要求设定为 0x00003000 ;另一方面,状态转移这一边也不可能只有 +4 一种情况,我们还要针对各种跳转添加不同的情况。看起来还是任重道远啊~
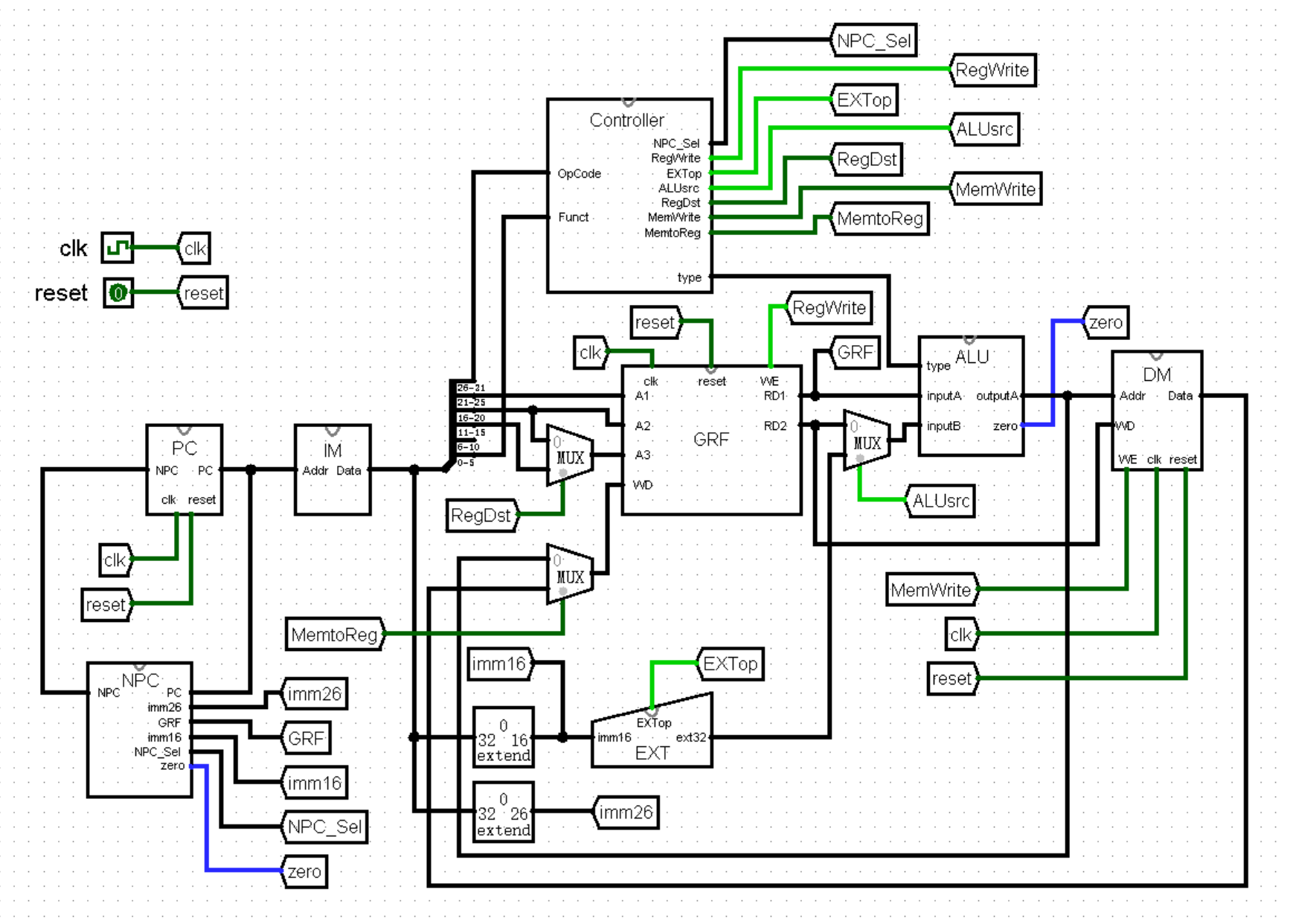
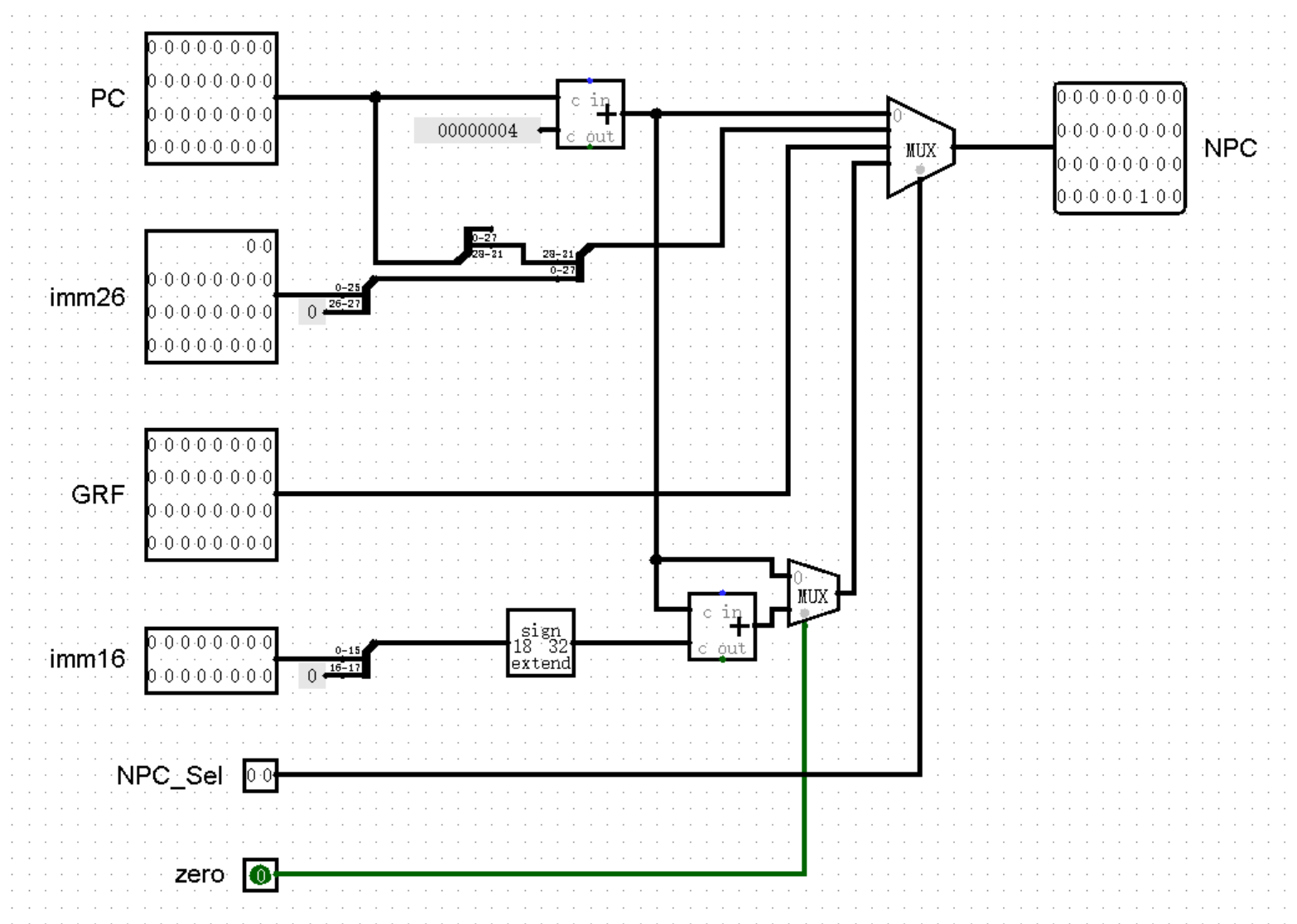
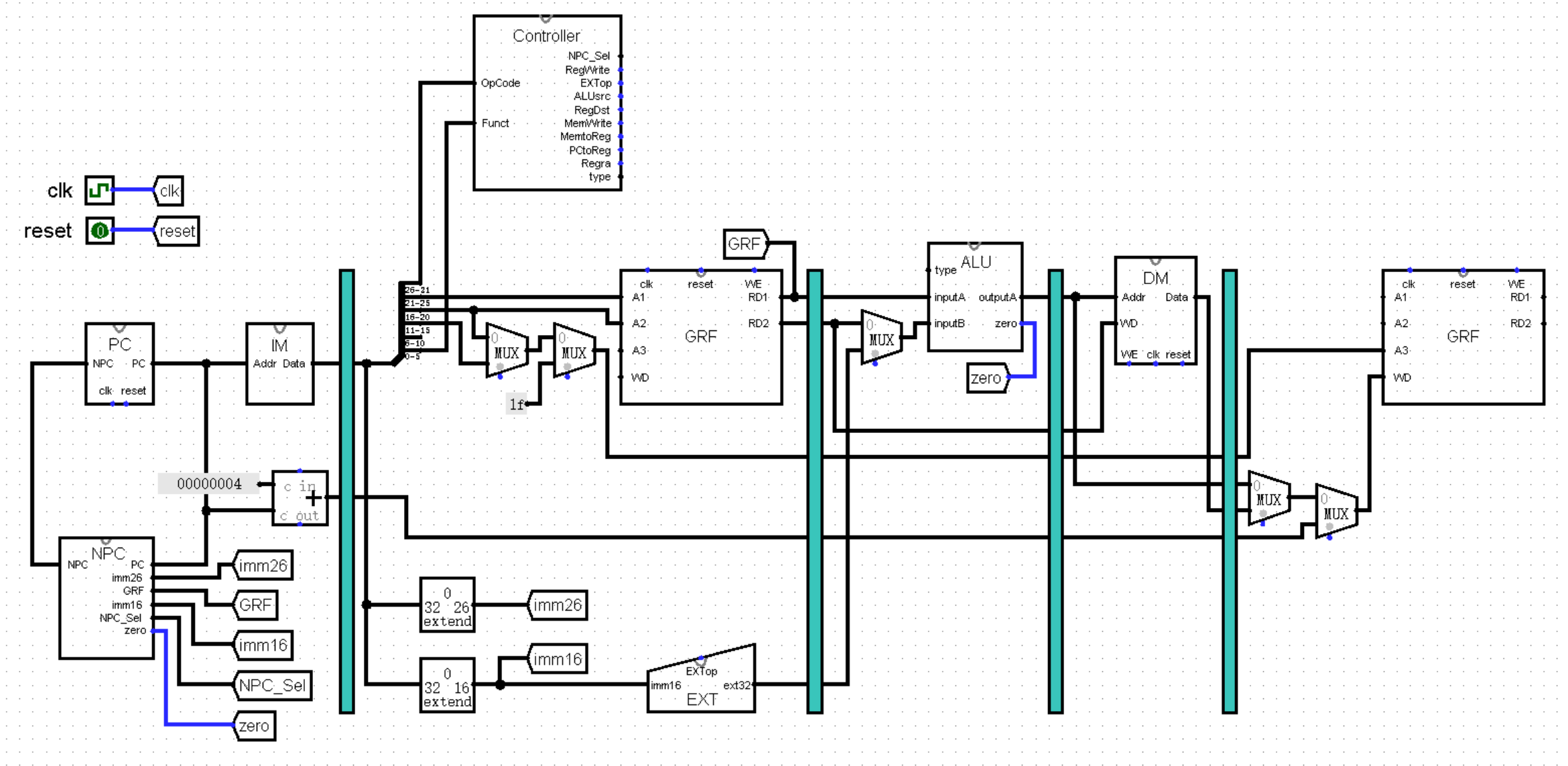
虽然我们确信已经找到了改进的思路,不过页面太小,我们好像实在有点画不下。于是,我们就可以考虑将电路拆成一个个模块,在模块内部实现其中的细节。例如,我们可以将 PC 寄存器整合为 PC 模块,将下方的状态转移部分整合为 NPC 模块,像下面这幅图片一样。你可能会觉得电路更加复杂了,是不是我在里面偷偷加了什么东西?实际上,这个电路和之前的是完全一致的:
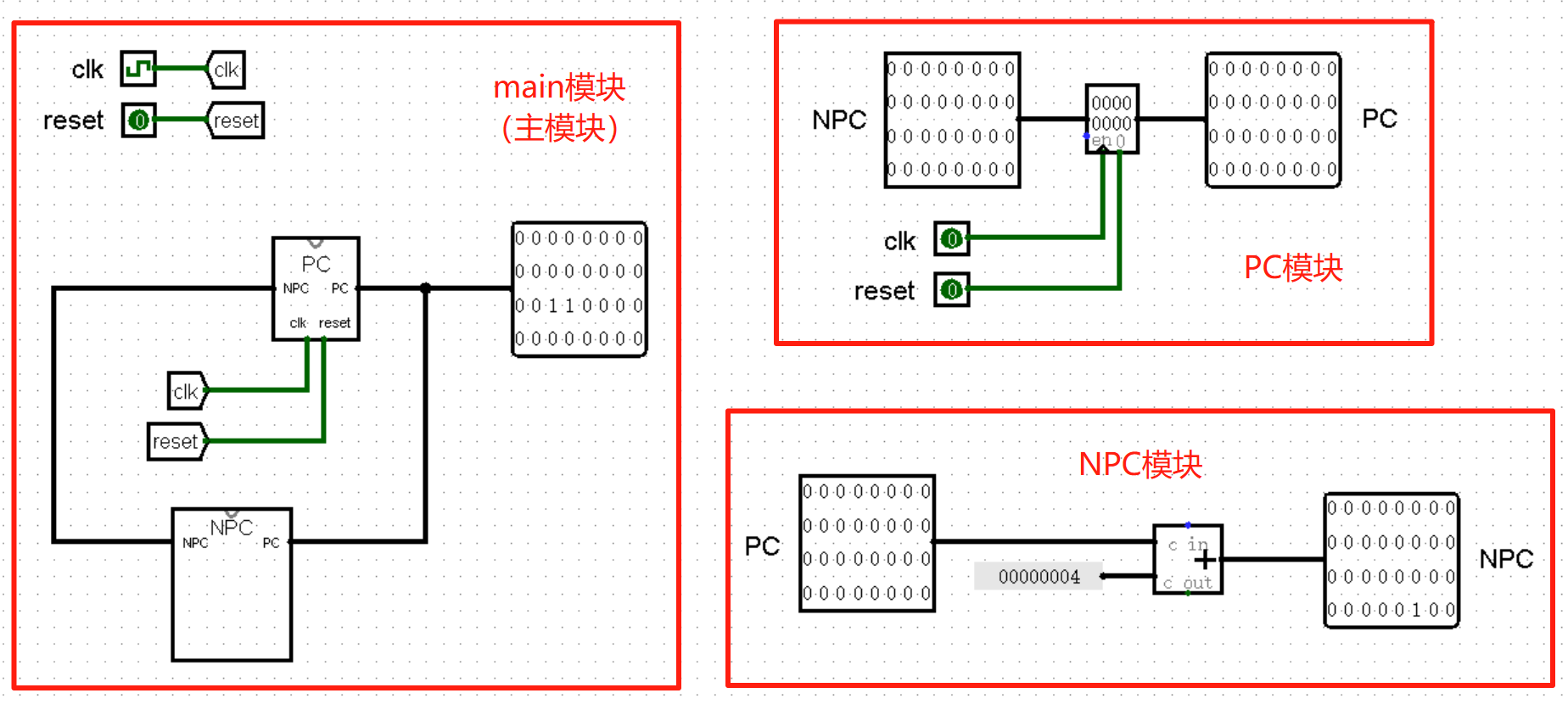
(这里为了方便观看,我把三个模块画到了同一张画布中,实际上它们应该在三张不同的画布中,相信聪明的你一定能理解的!)
上面这张图片中还是有很多细节的,以至于我需要单独拿出一大段文字,哪怕面临跑题的风险也要先解释一下:首先我们可以注意到,我在 main 模块中使用了 tunnel 元件连接 clk 和 reset ,在之后的搭建中,我们的电路会越来越复杂,适当使用 tunnel 元件可以让我们的电路看起来更加清爽!
接下来是 main 模块中对 NPC 模块的使用,你可能已经发现了,这里的 NPC 模块的输入端 PC 在模块的右侧,而输出端 NPC 反而在模块的左侧。如果你问我为什么这样设计,当然是为了好看了(笑)!要想实现这个效果也并不困难,只需要在设置模块外观时,将输入端口和输出端口的位置调换就可以了。
最后我还想提醒你注意一下 PC 模块中的 clk 端口。我们可以发现这个接口并没有使用时钟元件作为输入端,而是使用了普通的 input 元件作为了输入端。这是因为它实际上只是模块中的一个接口,真正连接时钟的位置其实在主模块中。如果在 PC 模块中就使用时钟元件作为输入端的话,PC 模块在外观上就会比正常情况少一个 clk 接口,没有办法连接到主模块的时钟元件上了。
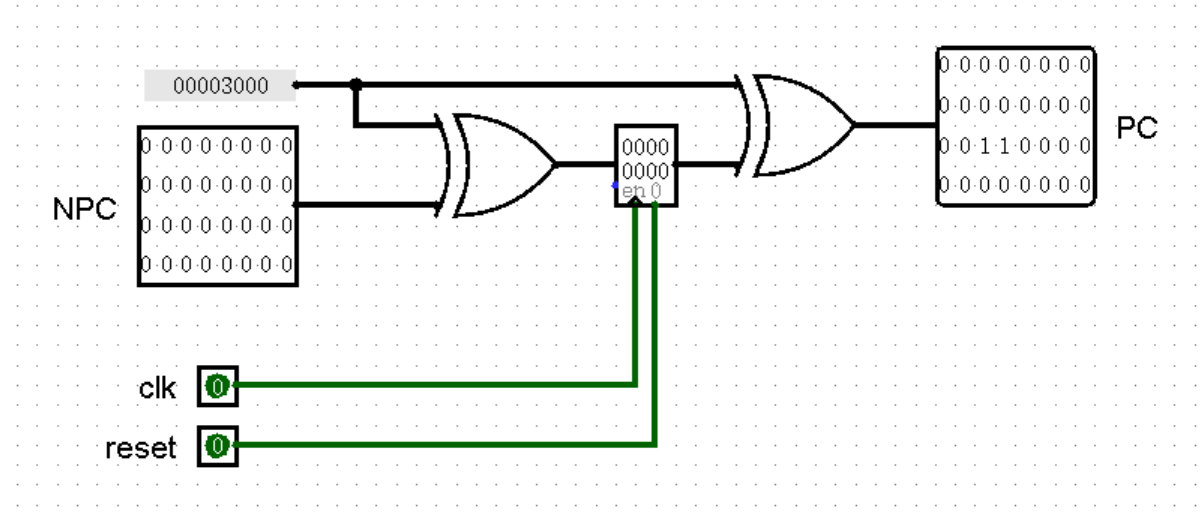
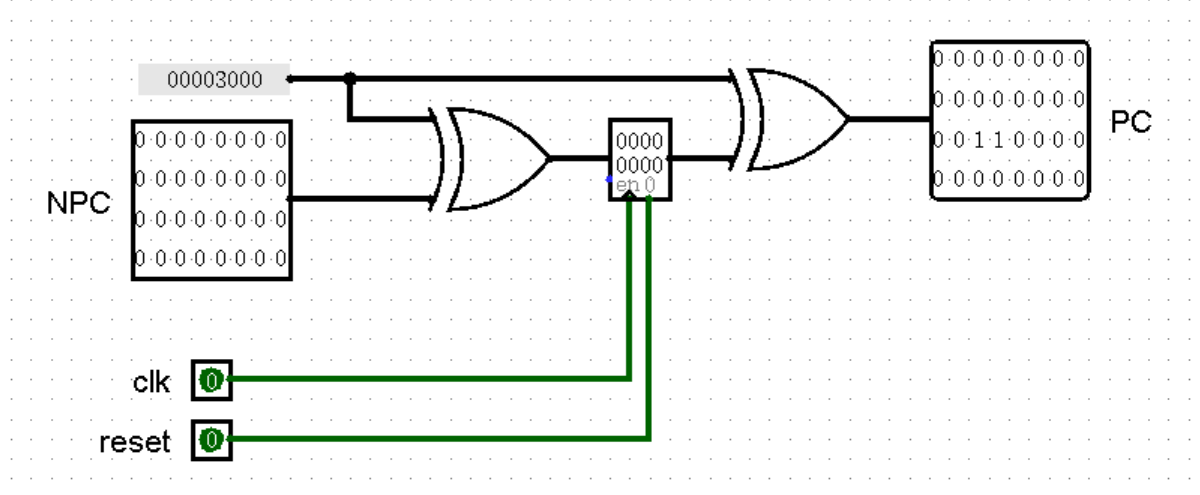
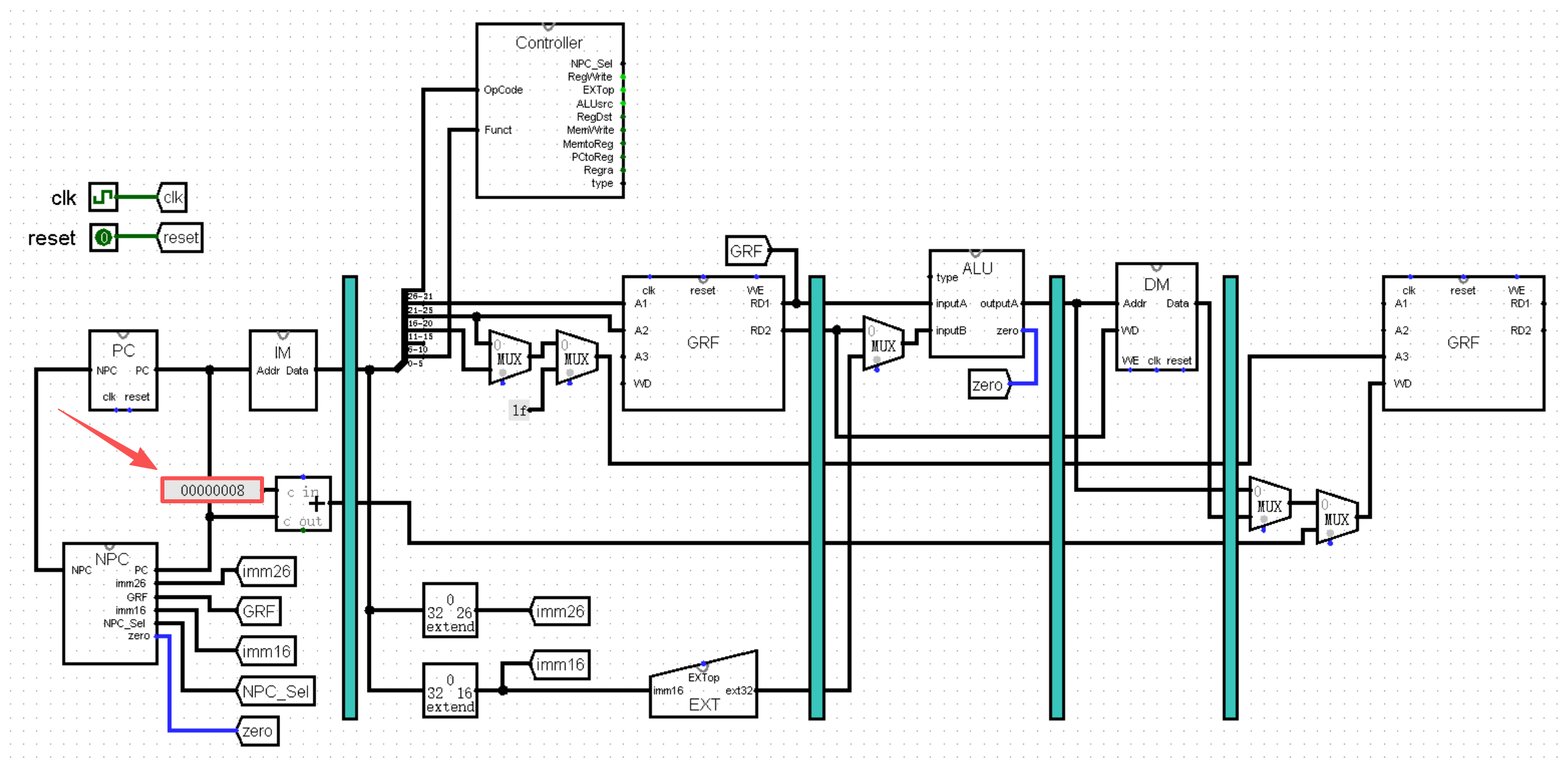
说了这么多,我们赶紧把话题拉回来,继续我们对 PC 和 NPC 这组状态机进行改造。首先我们可以为 PC 加上初始值。还记得我们在第一章讲过的双异或法吗?或许时间有些久远了,看看下面这幅图,不知道你能不能回忆起一些往事呢:
接下来就是为 NPC 支持适配跳转指令了。在跳转指令中,绝对跳转指令没有任何跳转条件,实现起来也是非常简单。对于 jr 和 jalr 指令,两条指令均是使用寄存器中 32 位的值作为跳转地址,也就是 NPC 模块的输出;而对于 j 和 jal 两条指令,我们还需要将指令中的 26 位立即数左移 2 位,并与当前 PC 寄存器的值的高 4 位进行拼接,才能得到跳转的地址。
这里我们可以先将上面的 32 位寄存器值和 26 位立即数统统作为 NPC 模块的输入,在后续环节中我们再考虑如何为 NPC 模块准备这些数据。那么到目前为止,我们就将 NPC 模块改造成了这样:
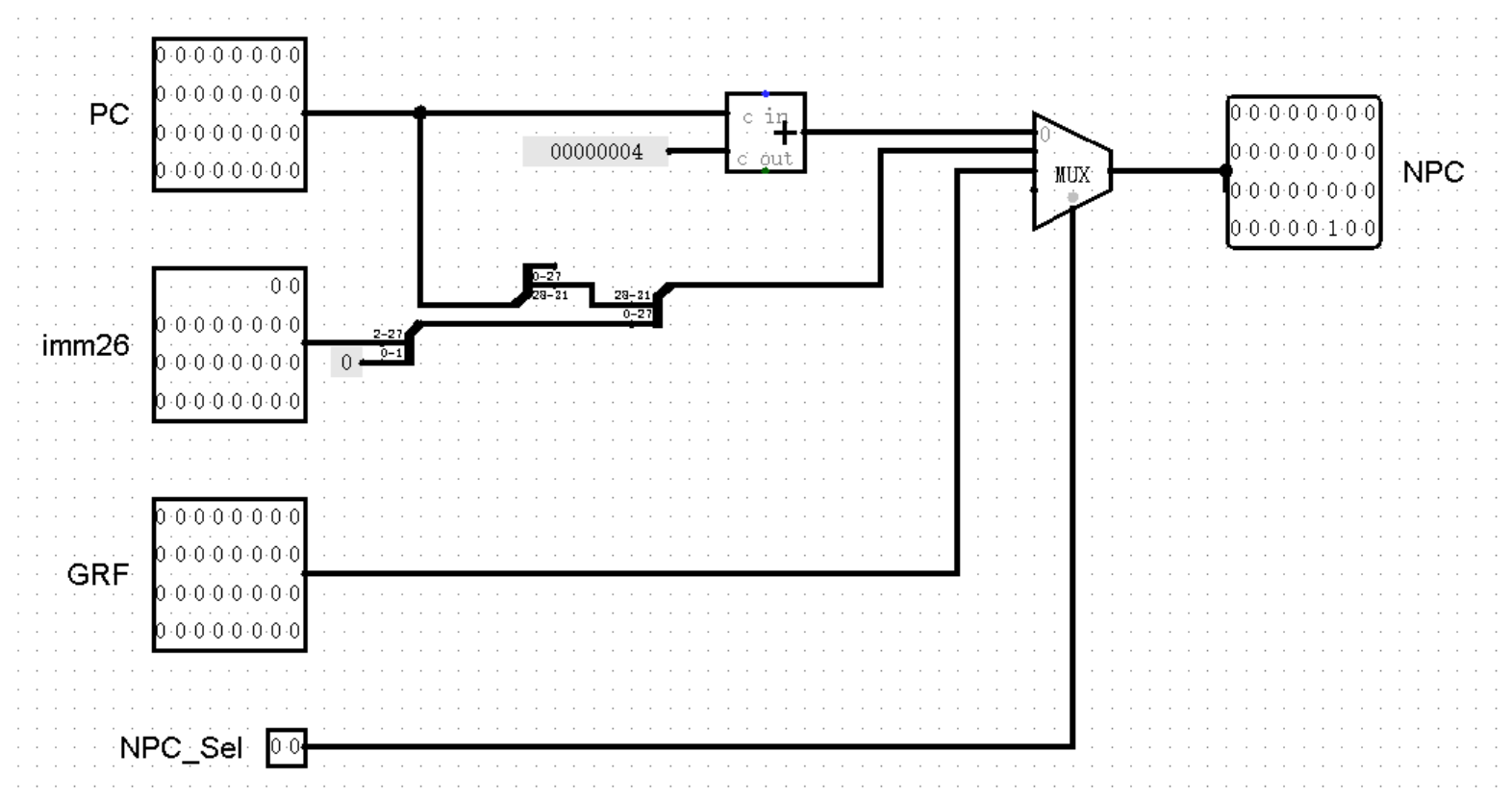
等等,下面这个 NPC_Sel 是哪里来的?定睛一看,原来是控制右侧的多路选择器 MUX 的选项,正是这个接口决定着下一条指令的地址是 PC + 4 ,还是 PC 与 26 位立即数 imm26 的复合,抑或是 GRF 中某个寄存器的值。在不久后我们搭建 Controller 模块时,就能够了解到它的来历了。不过我们现在还是争取来补全 NPC 的最后一块拼图 —— 相对跳转指令吧!
和绝对跳转指令不同的是,相对跳转指令是有条件的。当条件成立时执行跳转,下一条指令的地址变为 PC + 4 + sign_ext(imm16 << 2),当条件不成立时保持 PC + 4 。于是除了 NPC_Sel 这个选项,我们还需要额外引入一个 1 位的判断是否满足条件的接口,祖上传下来的规矩,喜欢把这个接口叫做 zero ,我也不知道为什么。
不过叫什么名字不要紧,最重要的是我接下来的一番话,想当年我就是因为没有参透这句话,差点在 P3 就翻了大车,也让 P3 成为了我唯一一个没有 AK 过的 P ,非常遗憾。这句话就是:当我们添加新的信号接口时,一定要注意新接口的值是否会对已有的指令产生影响! 例如在下面两种 zero 接口的实现中,哪一种实现方法中,zero 的值会对除相对跳转指令的其它指令也产生影响呢?
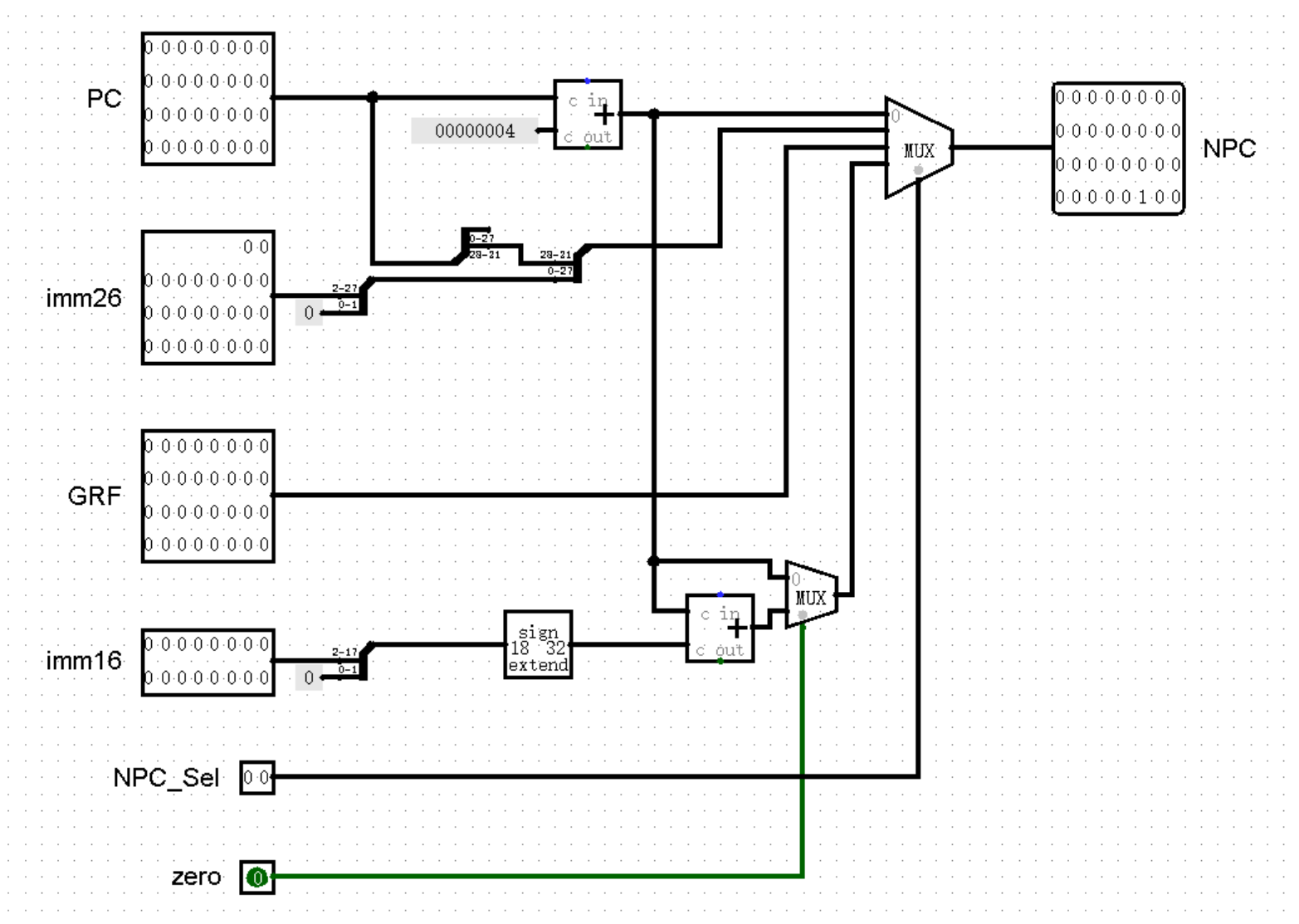
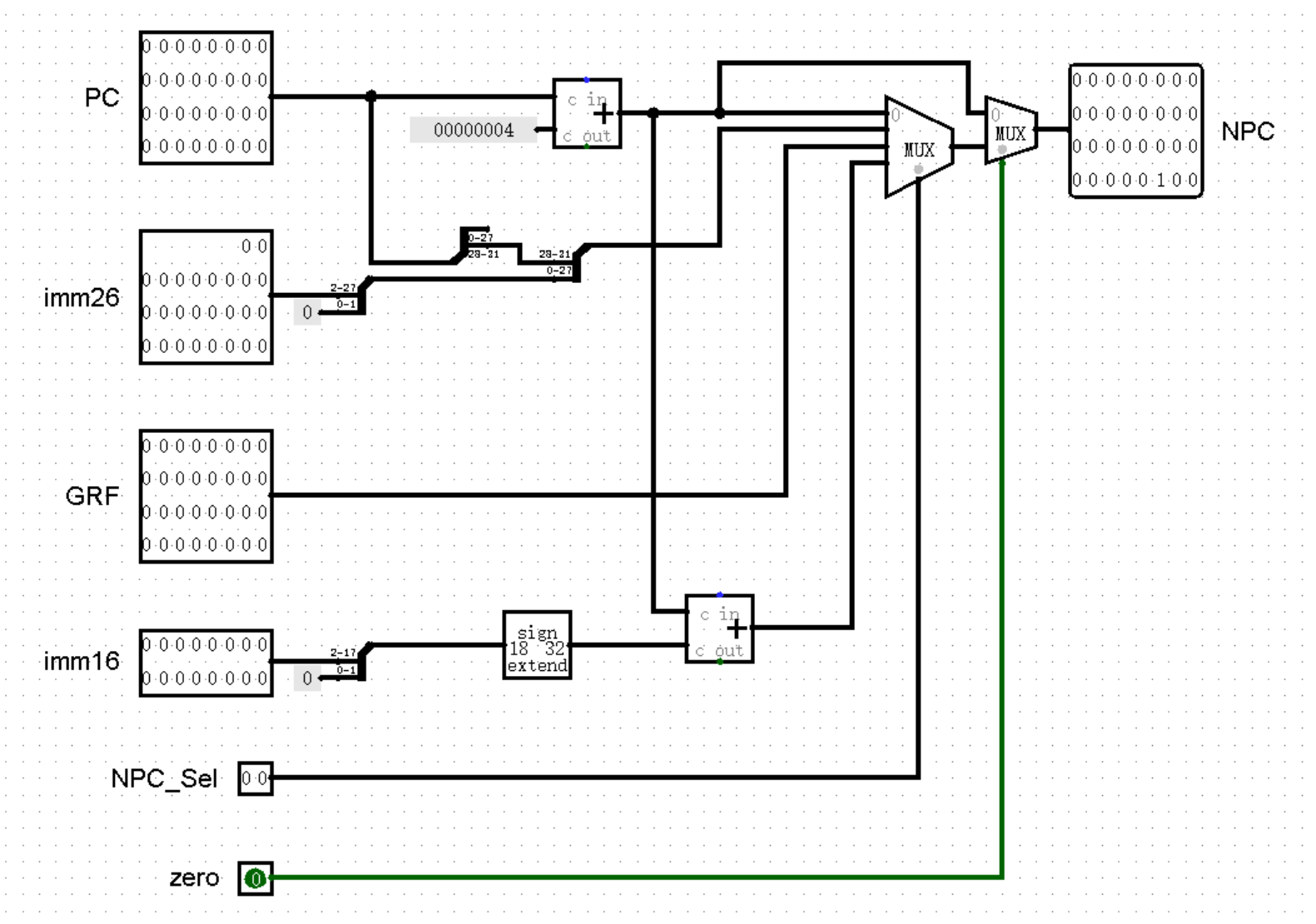
答案是下面一种,你答对了吗?我们观察两个电路,在上一幅电路图中,当 NPC_Sel 的值不为 3 ,也就是当前指令不是相对跳转指令时,zero 的值无论为多少,都与输出毫无关系;而在下一幅电路图中,我们会发现即使 NPC_Sel 的值为 1 或 2 ,即当前指令为绝对跳转指令时,也需要 zero 的值为 1 才能够正常跳转,否则依然会输出 PC + 4 !
这并不是说后者的实现是错误的,实际上,只要我们在根据指令类型为 zero 赋值时,记得将绝对跳转指令对应的 zero 值无条件赋为 1 ,即可正确实现电路。不过为了保险起见,也是为了我们在上机考试中加指令能够更加顺利,我们在之后的教程中将会使用前者的实现方法。
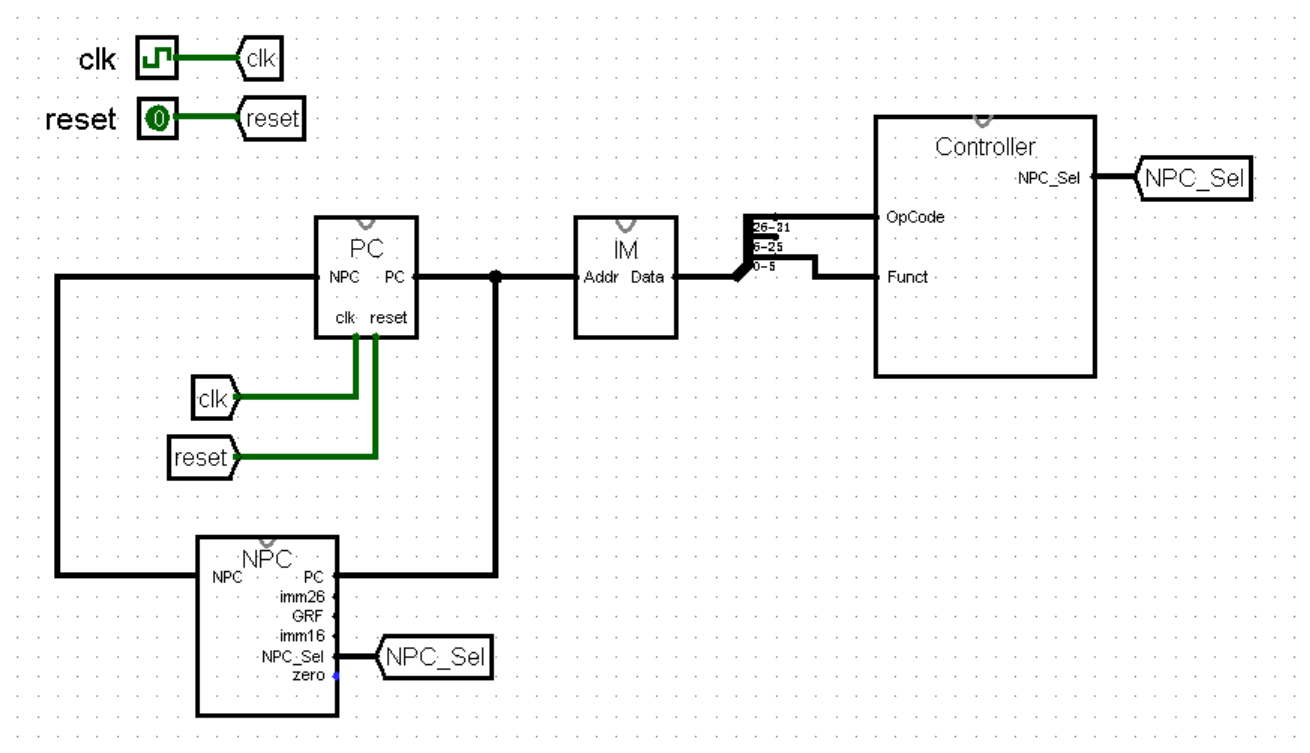
终于,我们完成了 PC 和 NPC 这组状态机,成功得到了当前指令的地址,在正确取出指令的路上迈出了一大步!接下来,我们来完成 IM 模块,将地址转换为 MIPS 指令的机器码。
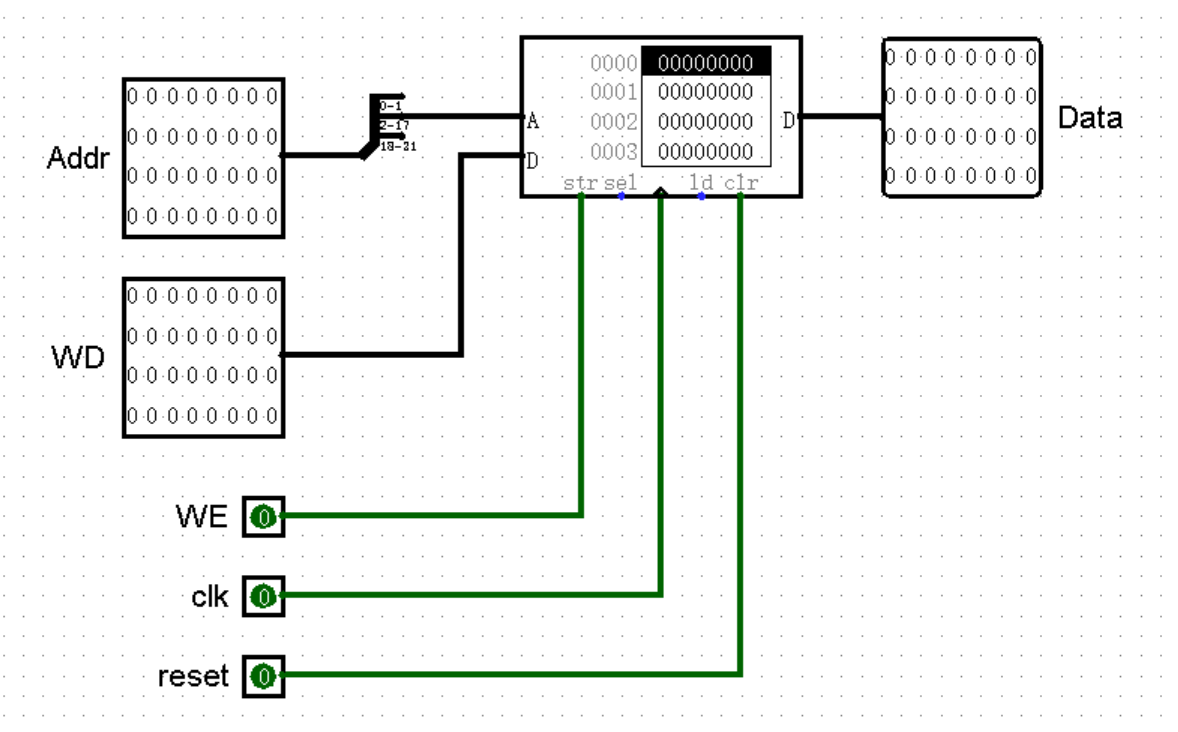
我们知道,指令的存储需要用到一大片连续的地址空间,使用最高只有 32 位的寄存器堆可能并不是一个非常好的方法。好在我们还有两个量大管饱的高手能够解决这个问题,那就是 ROM 和 RAM ,在这里我们选择 ROM 作为存储指令机器码的载体。ROM 的特点是只能在程序运行前将内容一次性全部写入,而无法在程序运行过程中进行任何修改。在程序运行过程中,我们当然不希望程序遭到篡改,于是选择 ROM 就再合适不过了!
我们创建一个 IM 模块,在模块中放置一个 ROM 元件。接下来,我们就可以把汇编程序的机器码导入 ROM 中了。如果你忘记了怎么在 MARS 中将汇编程序的机器码导出为 txt 文件,以及如何在 Logisim 中将 txt 文件格式的机器码导入 ROM 中,那么快回头看一看上半本书的内容吧!我会等着你回来的!(笑)
我们观察可以发现,ROM 左侧有一个输入端 Address 端,右侧有一个输出端 Data 端。(下方的 Select 端我们暂时不需要用到)为了使 ROM 的 Data 端能够一次性输出 32 位的指令,我们在左下角的设置中,将 ROM 的 Data Bit Width 改为 32 。
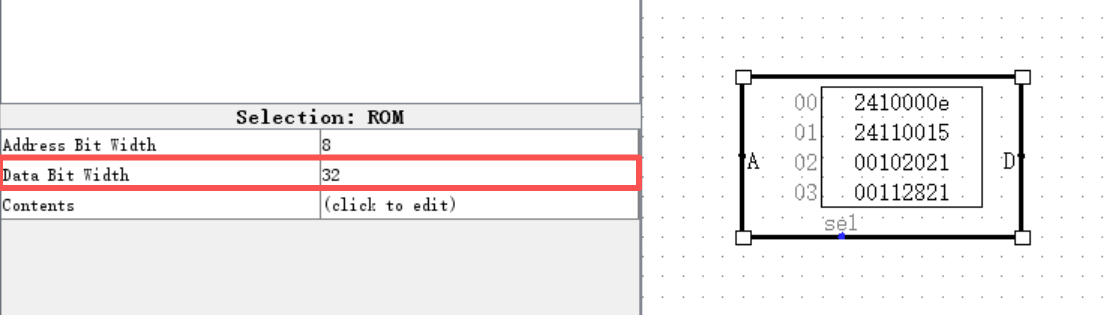
接下来我们来关注 ROM 左侧的 Address 端,Address 端输入的内容就是指令的地址吗?答案显然是否定的。最明显的一个问题,ROM 中指令机器码的首地址是 0 ,而不是 0x3000 ,所以我们在将地址输入 ROM 之前,需要事先减去一个 0x3000 。
然而这就可以了吗?我们试着给 ROM 的 Address 端赋不同的值作为输入,观察输出的结果:
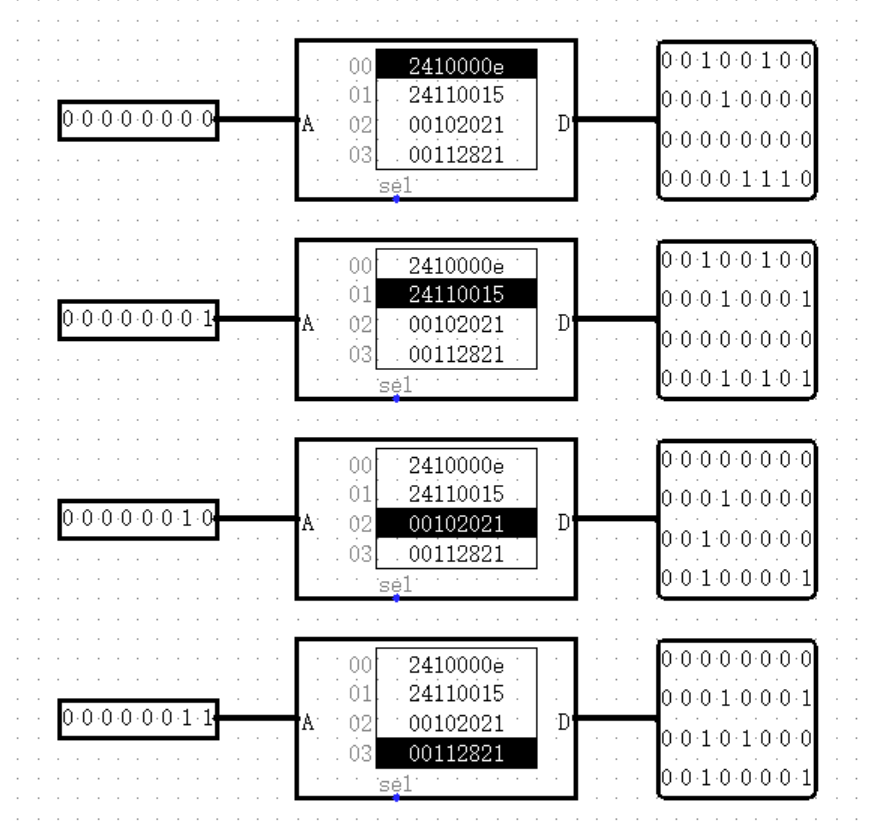
于是我们能够发现,相邻两条指令之间的输入值并不像指令地址一样相差 4 ,而是相差 1 。所以我们在 -3000 之后,还需要再除以 4 ,也就是右移 2 位。
结束了吗?似乎并没有。当我们满心欢喜以为做好了所有前期工作,准备设置 Address 端的位宽时,却发现我们最大只能设置 24 位的位宽!实际上,Logisim 中 ROM 的存储空间也是有上限的,所以我们只能委曲求全,牺牲一些地址空间,舍去地址中最高的几位了:
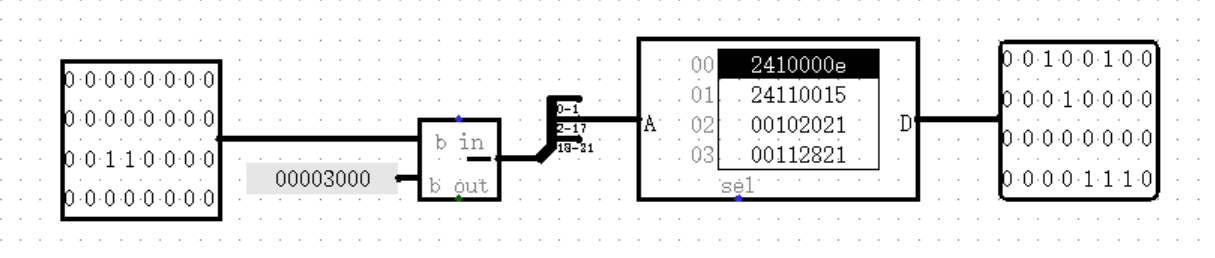
(图中截取了地址的第 2 到 17 位,也就是保留了 16 位的 Address 位)
最后,我们把 IM 连接到电路上,就完成了我们 CPU 中取指令的全部内容!
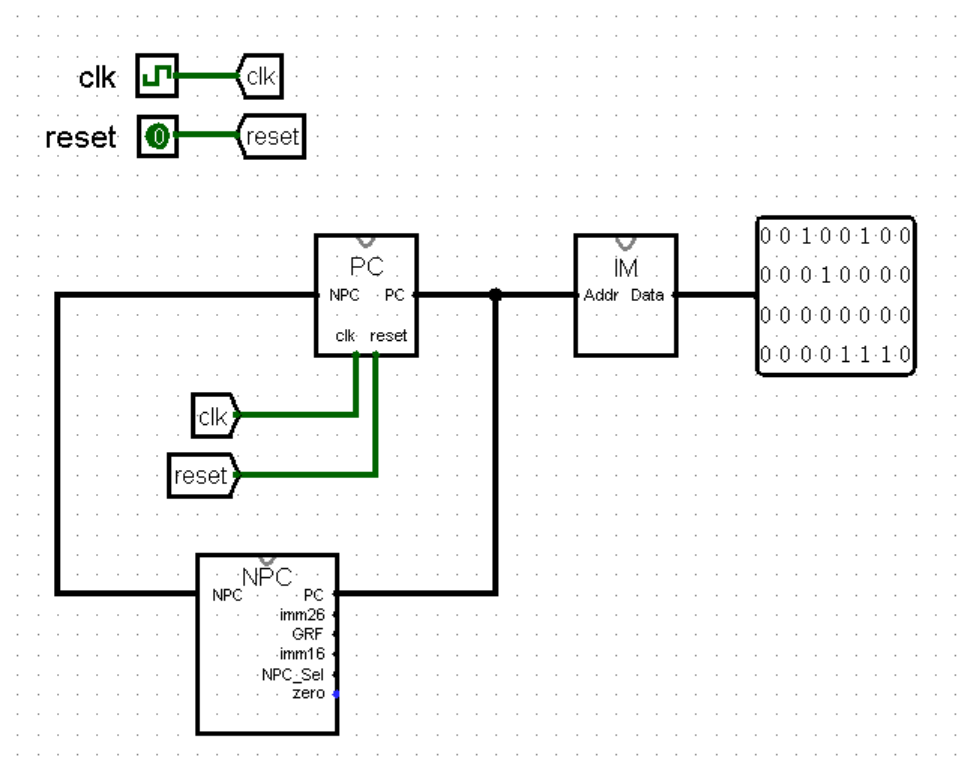
【控制器:Controller模块】
历经了千辛万苦,我们终于取出了要执行的指令。接下来,我们就要进入执行指令的阶段了。那么,我们该如何实现将如此多种指令的执行集成到一个 CPU 上呢?
首先我们肯定知道,每种指令的执行过程都是不同的(这不废话嘛)。即使我们将所有指令的所有共通之处都整合起来,也依然会出现许多差异,这就需要我们的 CPU 根据指令的种类进行分类讨论了。
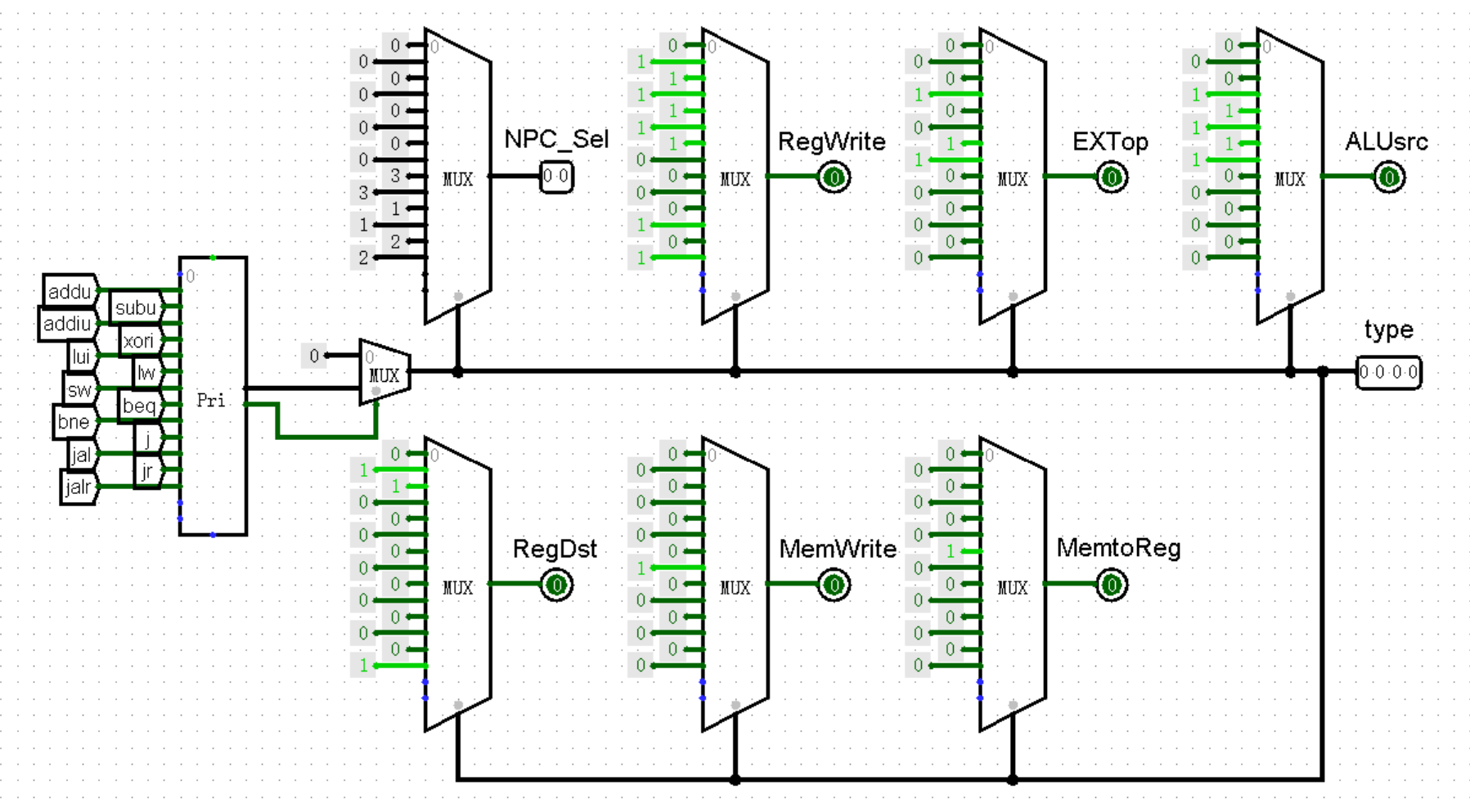
于是我们就需要发明这样一个模块,它有两个功能:一是根据指令的机器码解析出指令的名称;二是根据解析出的名称为一些存在差异的接口赋值(例如 NPC 模块中的 NPC_Sel ,还记得吗)。那么恭喜你发明了 Controller 模块!
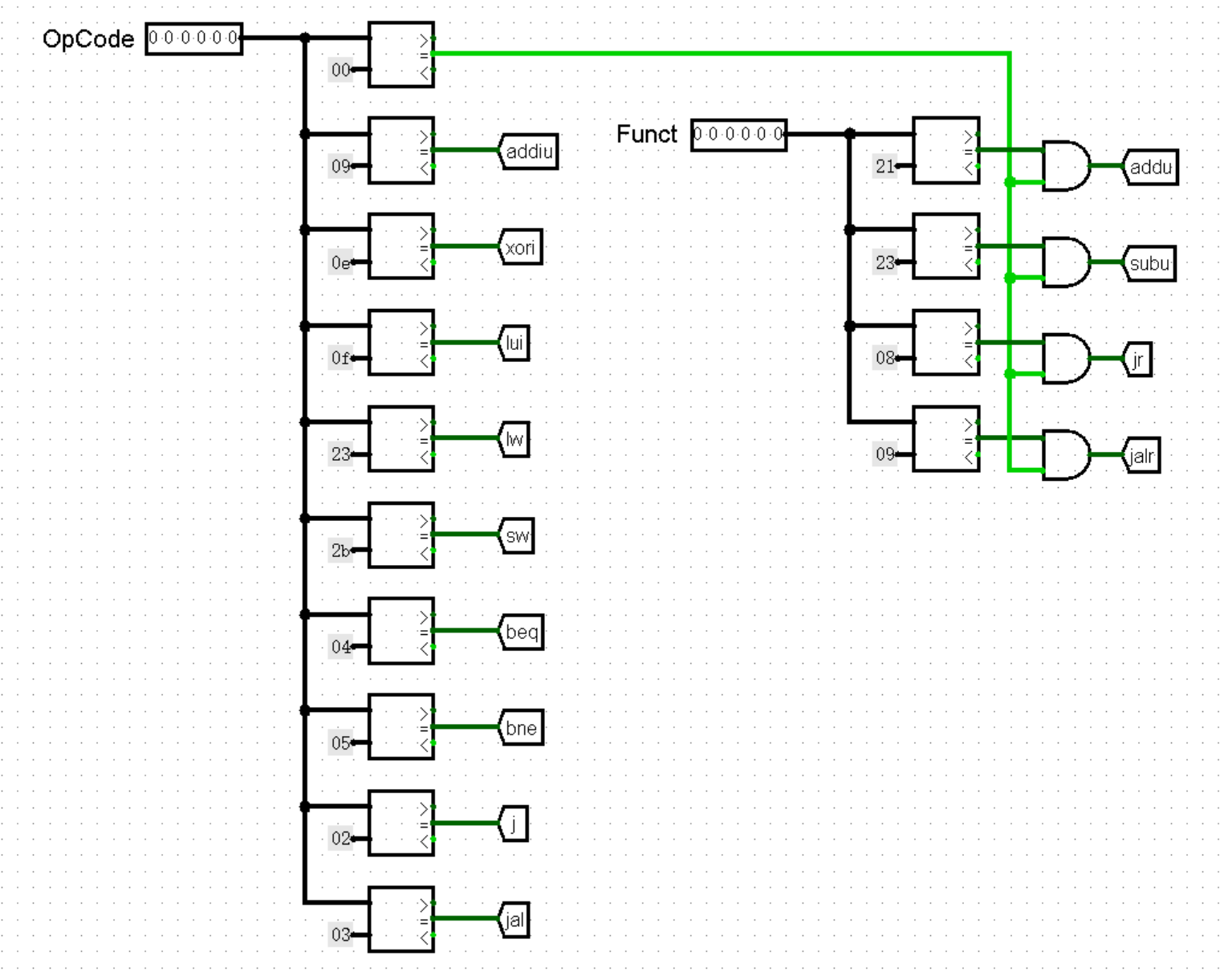
接下来,我们跟着上面的思路,分两步实现 Controller 。首先我们需要根据指令的机器码判断指令的名称。我们知道,对于绝大多数指令来说,通过最高 6 位的 OpCode 和最低 6 位的 Funct 都足以判断指令的类型了(当然像 bltz bgez 这种奇葩除外,不过我们目前可以不考虑这些)。于是我们从指令的机器码中分离出这两个部分,作为 Controller 的输入:
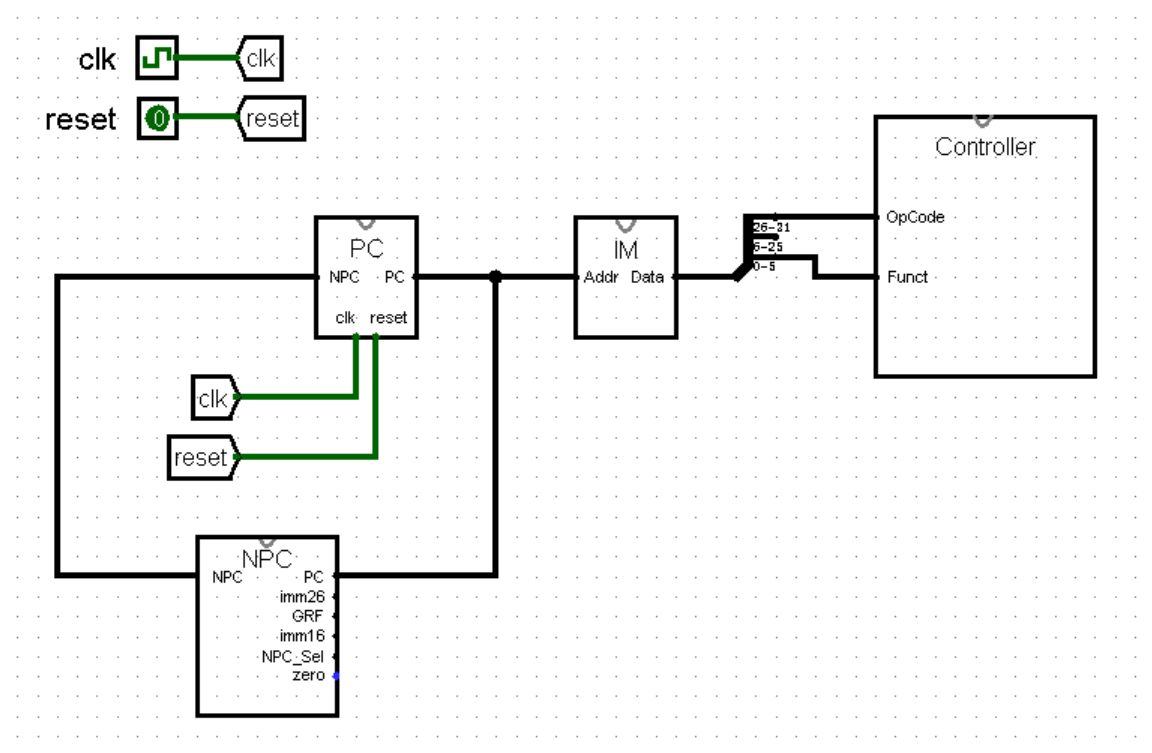
在 Controller 中,我们将 OpCode 和 Funct 与各种指令的值进行比较。需要注意的是,只有当 OpCode 为 0 时,才允许继续比较 Funct ,否则可能会出现某种 I 型或 J 型指令的最低 6 位恰好和某指令的 Funct 相等的情况,导致我们的 CPU 将一条指令同时判定为两种类型的奇葩情况:
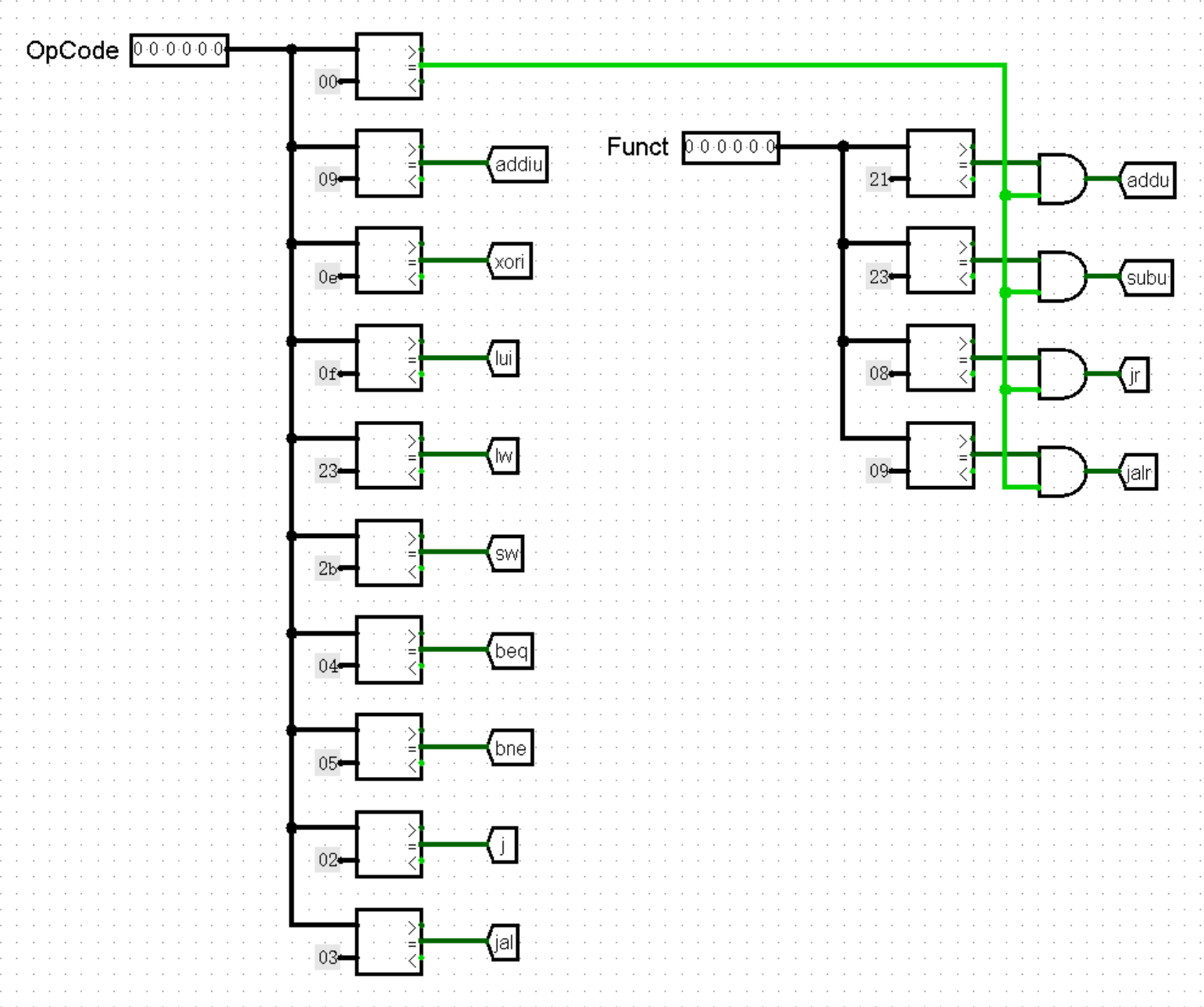
( nop 指令不需要单独判断,我们将 nop 指令与其它所有的未知指令并入一起,当所有指令的判断全部为 0 时即为这种情况)
我们不难发现,在这种结构下,上面的所有 tunnel 中最多只有 1 个值为 1 ,其余一定都为 0(当然也可能会出现全部为 0 的情况,比如 nop 指令),所以我们可以说这就是一种独热码。
接下来,我们要对每种指令规定每一个接口的值,也就是将这些 1 位的独热码转换为对应接口的输出。例如当指令为 addiu 时,NPC_Sel 接口的值应该等于多少;当指令为 beq 时,NPC_Sel 接口的值又应该等于多少。
或许你已经想到了一种非常简单的方法,那就是使用 Logisim 中自带的功能,将真值表一键转换为电路图。但是实际上我并不推荐这种做法,因为 Logisim 只能保证生成电路的正确性,却没有办法保证它的清晰度和可扩展性。当你紧张地坐在上机考试的考场上,面对着一坨乱七八糟的与或非门,如同不可名状之物缠绕在一起的时候,相信我,你的 SAN 值直接就掉光了!
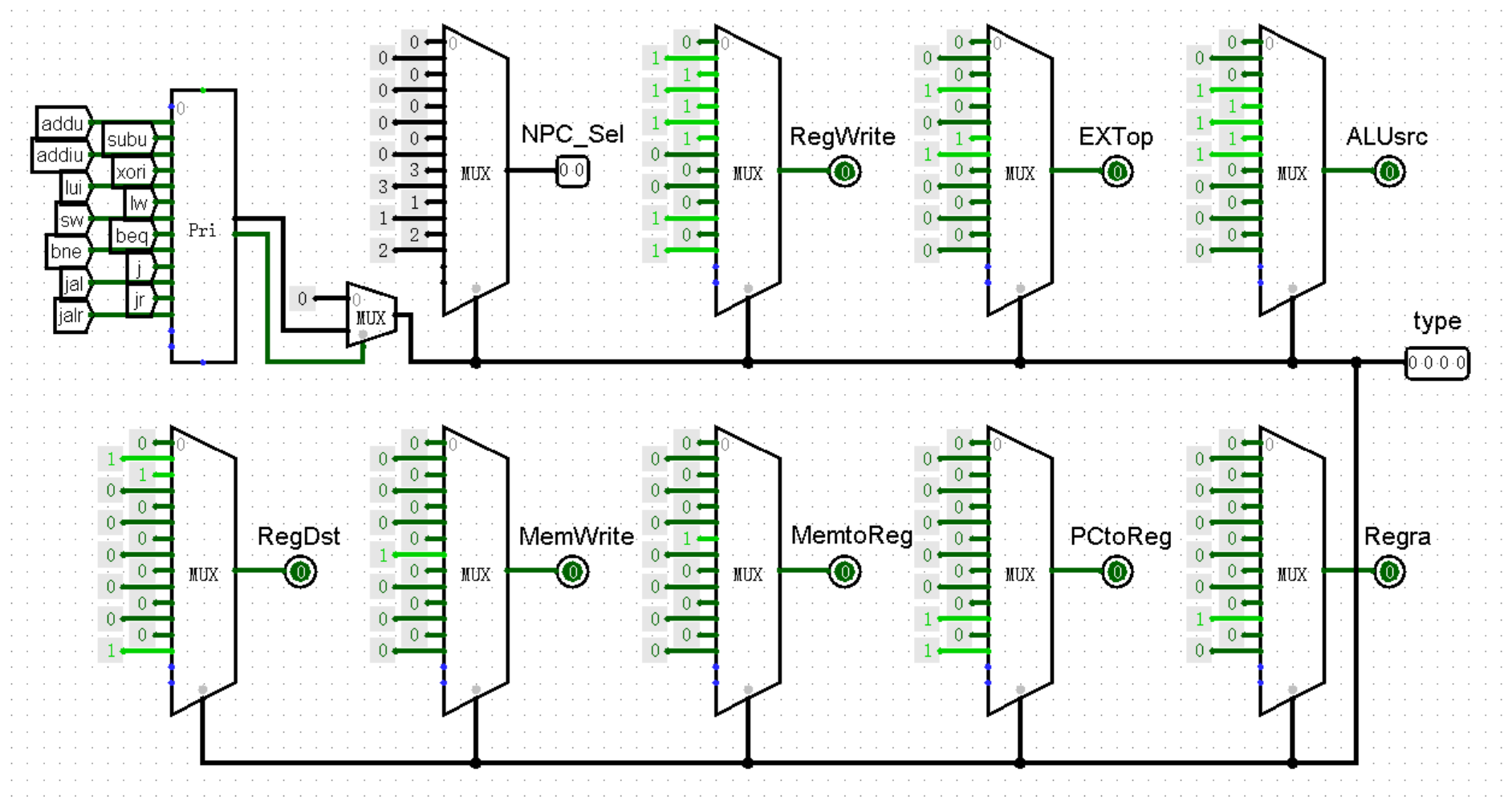
相反地,我将提出一个更加工整简洁的方法!如果我们想根据不同情况对接口赋值,我们最先想到的一定是使用 MUX 元件。不过,MUX 元件的选择端要求我们输入数字序号,而不是一个一个的独热码,有没有什么元件能够快速解决这个问题呢?
或许你可以试试被尘封许久的优先编码器 Priority Encoder !上半本书中我好像还说过它的坏话,不过现在看来它还是有点用处的。对于独热码来说,独热码最多只有 1 个输入端的值为 1 ,那么优先编码器就会直接输出这个 1 所在的位置,也就实现了将独热码转换为顺序编码!
不过我们还需要注意一个细节,那就是还有可能会出现所有输入端均为 0 的情况,此时优先编码器的输出就会全变成 X 。为了解决这种情况,我们可以使用输出下方另外的一个 1 位输出进行辅助,当输入端全为 0 时输出为 0 ,否则输出为 1 ,搭配 MUX 元件进行选择,就可以实现对 nop 指令以及其它未实现指令的判断了:
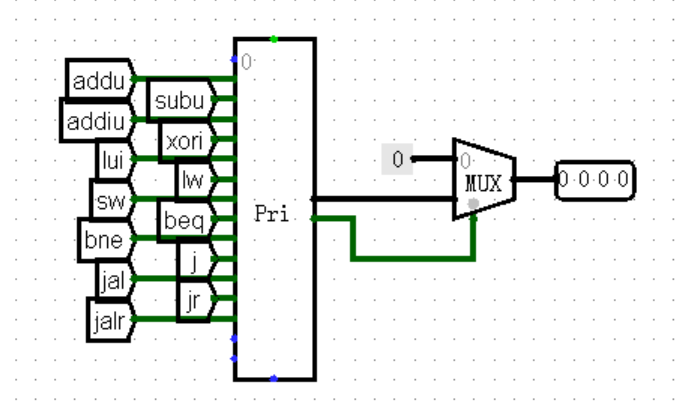
将独热码转换为数字之后,我们就可以将其接入 MUX 元件,根据指令在优先编码器左侧的顺序,为每条指令编写接口的值了。这种做法不仅支持无限堆叠接口,在上机时也能够更加轻松地完成加指令的任务:
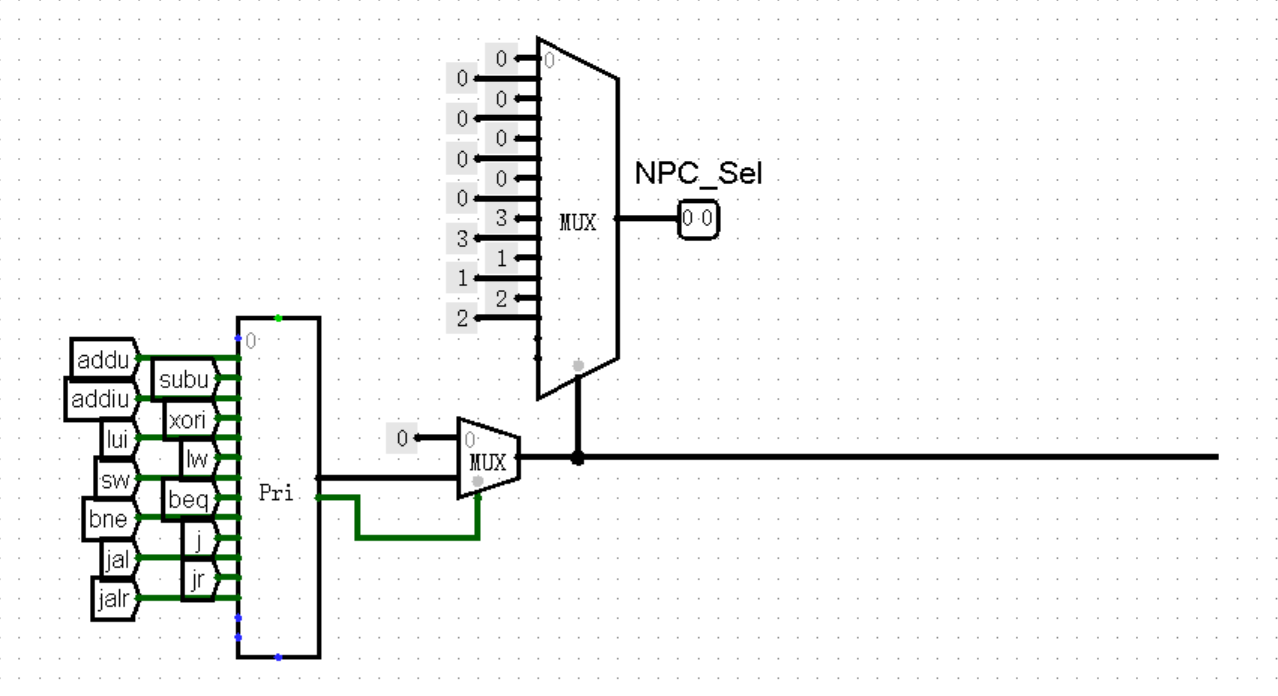
最后,我们修改 Controller 模块的外观,将输出端的 NPC_Sel 接口与 NPC 模块上的对应接口连接起来就可以了:
Controller 模块作为控制每条指令行为的核心,在接下来加指令的过程中会不断添加接口,我们可以在这里设一个存档点,记得常回家看看~
【R型计算类指令与GRF、ALU模块】
接下来,我们开始为我们的 CPU 加入各种指令,我们从 addu 和 subu 这两条 R 型计算类指令开始。我们分析这两条指令的执行流程,大致需要进行这样的几步操作:
- 取出 rs 和 rt 两个寄存器中的值
GPR[rs]和GPR[rt]; - 对
GPR[rs]和GPR[rt]进行运算; - 将运算结果写入 rd 寄存器中。
其中,第 1 步和第 3 步都需要与寄存器堆 GRF 进行交互。我们来观察交互的需求:第 1 步要求我们同时向 GRF 输入两个 5 位的寄存器编号,并要求寄存器同时输出对应的两个寄存器中 32 位的值。我们将两个输入端记为 A1 和 A2 ,将两个输出端记为 RD1 和 RD2 ;第 3 步要求我们向 GRF 输入一个 5 位的寄存器编号,同时输入一个 32 位的值,要求 GRF 将这个值写入对应的寄存器中。于是我们将这两个输入端分别记为 A3 和 WD 。
除了上面提到的 4 个输入端口和 2 个输出端口之外,GRF 还应该再设置一些端口,比如控制其中所有寄存器的 clk 和 reset 端口,另外还应该有一个写使能 WE 端口。这个写使能端口的作用是什么呢?这就很考验我们的全局意识了!众所周知,虽然 addu subu 这些指令有向寄存器赋值的环节,然而并不是所有指令都是这样,例如 beq j 等指令,可以说是比比皆是。为了在执行后者这些指令时不把一些奇怪的值写到一些奇怪的寄存器中去,我们就需要为 GRF 加上 WE 这样一个写使能,当执行这些指令时置 0 ,这样就很好地解决了这个问题!
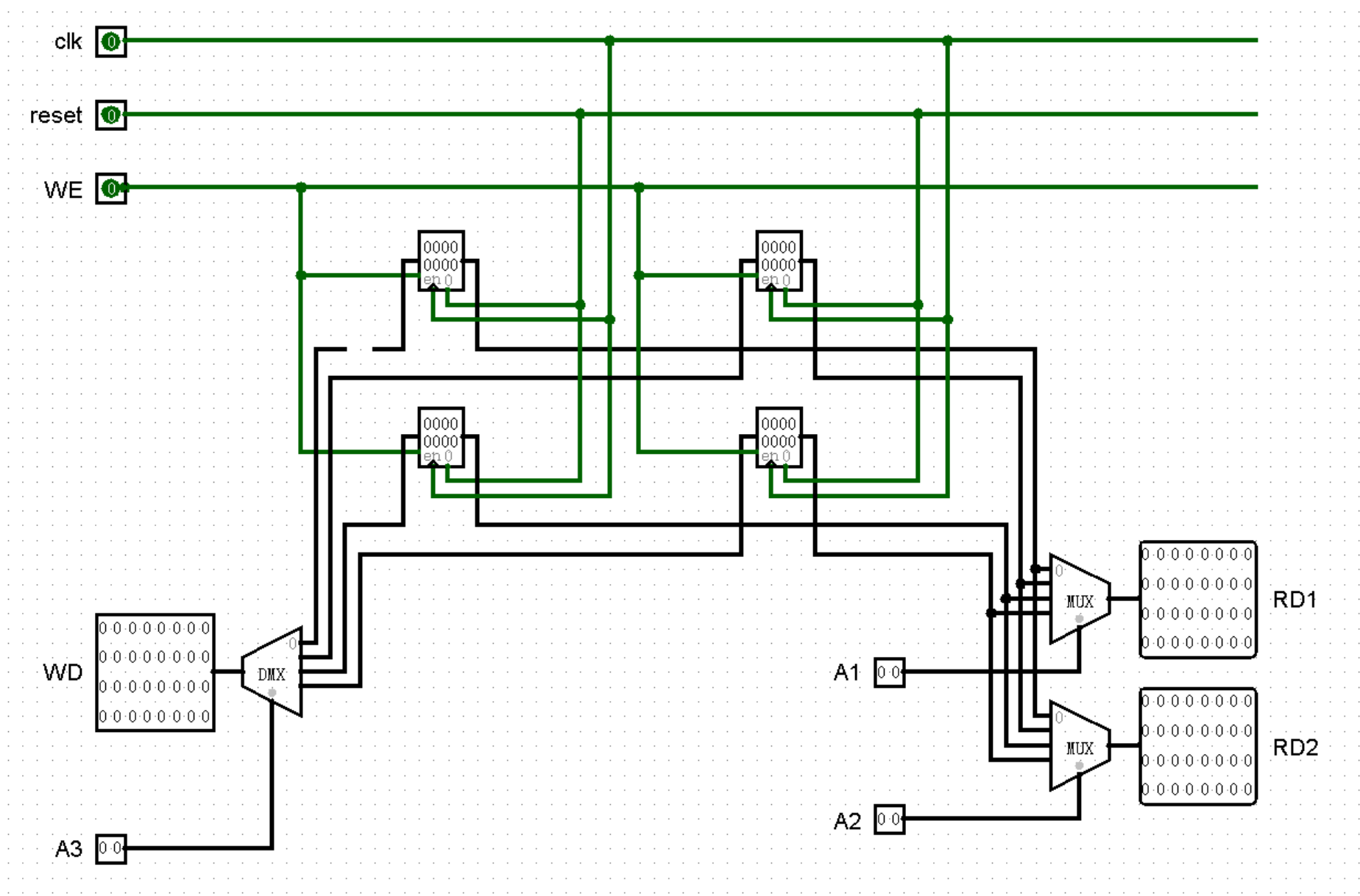
接下来我们来着手搭建一下 GRF 模块。可以预见的是,32 个寄存器必然会导致我们的电路图来到一个极其凶残的超大规模,不过其实都是一些重复性较强的简单工作,只不过是力气和时间的问题。为了让大家能够看清楚,接下来的样例图片中以 4 个寄存器作为例子,大家在搭建的时候自行扩展为 32 个寄存器即可~
首先,我们为我们的小寄存器堆添加时钟信号 clk 、复位信号 reset 和写使能 WE :
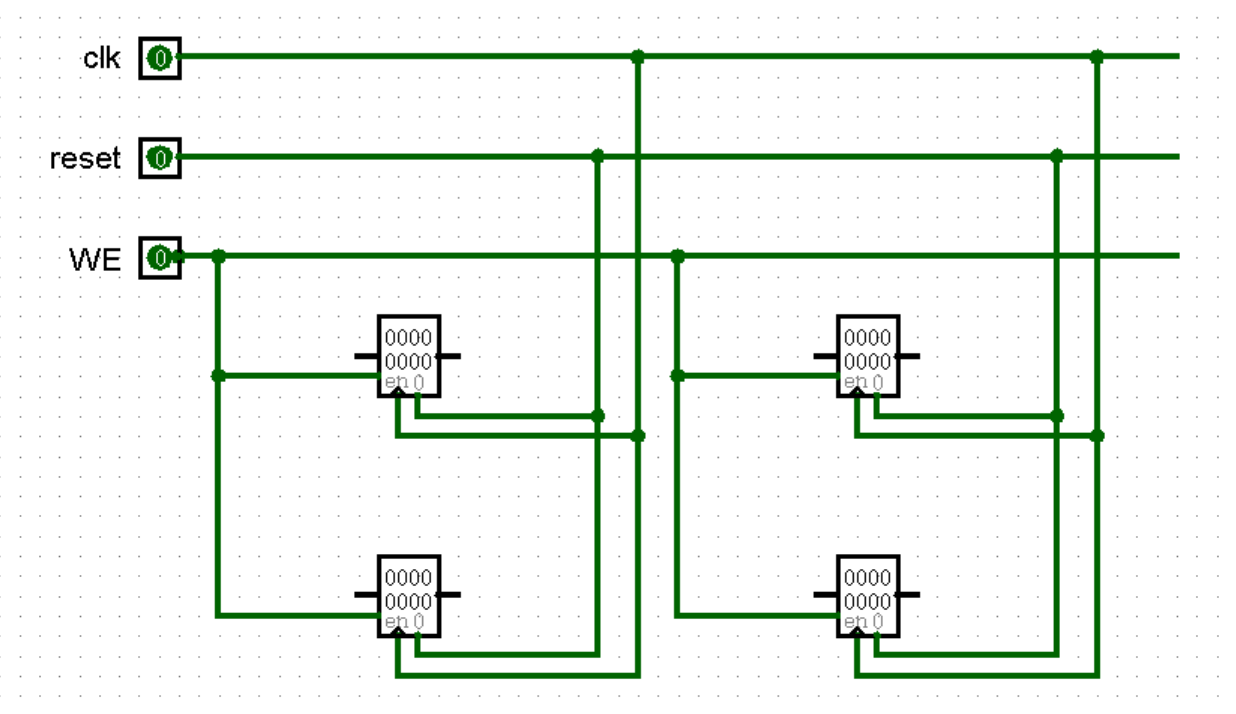
接下来,我们为小 GRF 加上 A1 A2 两个输入端和 RD1 RD2 两个输出端,使用 MUX 元件就可以轻松完成这个任务:
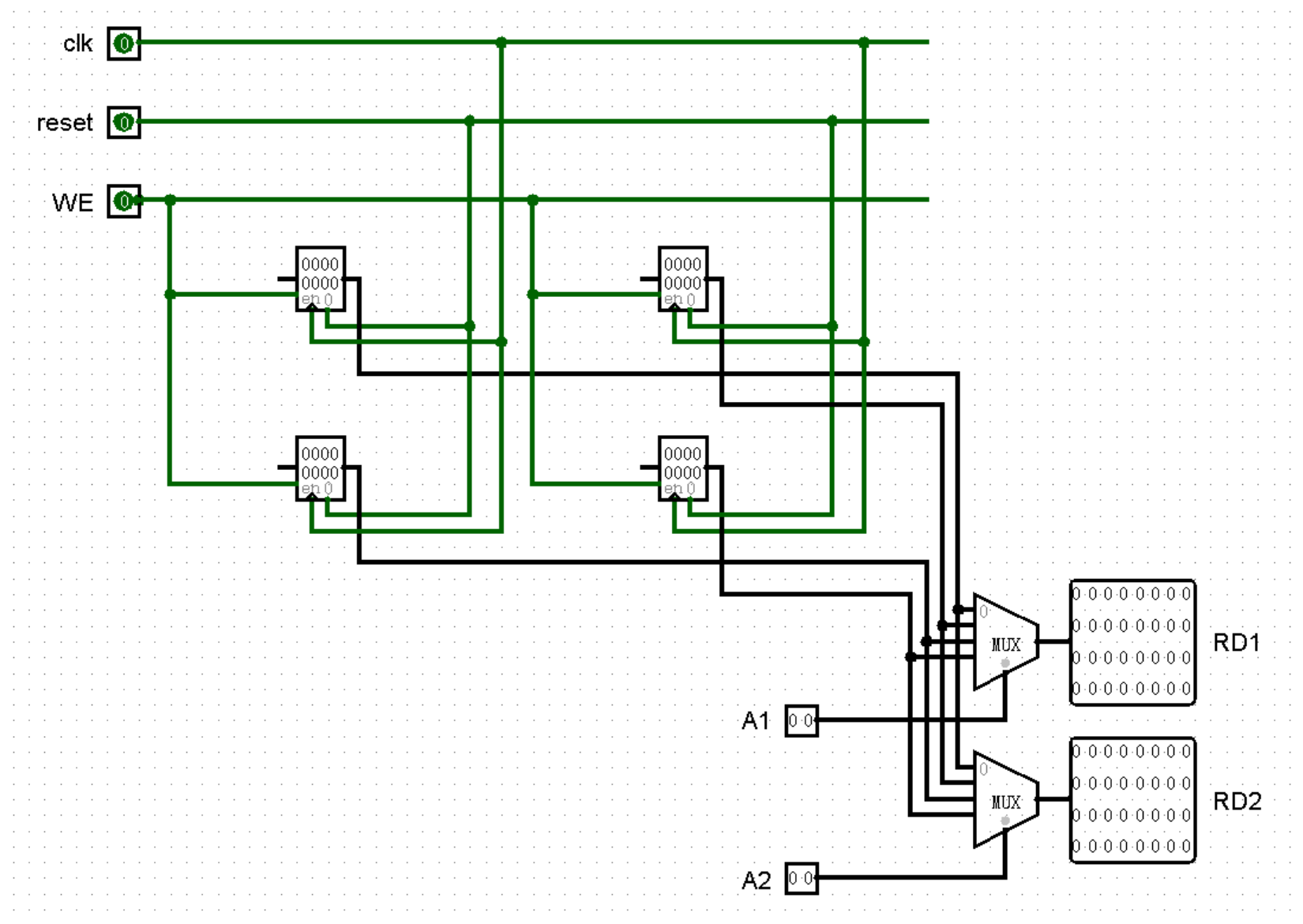
这个走线实在是说不上优雅……算了无所谓了,我们继续为小 GRF 加上 A3 和 WD 两个输入端,这一次我们使用许久不见的 DMX 元件:
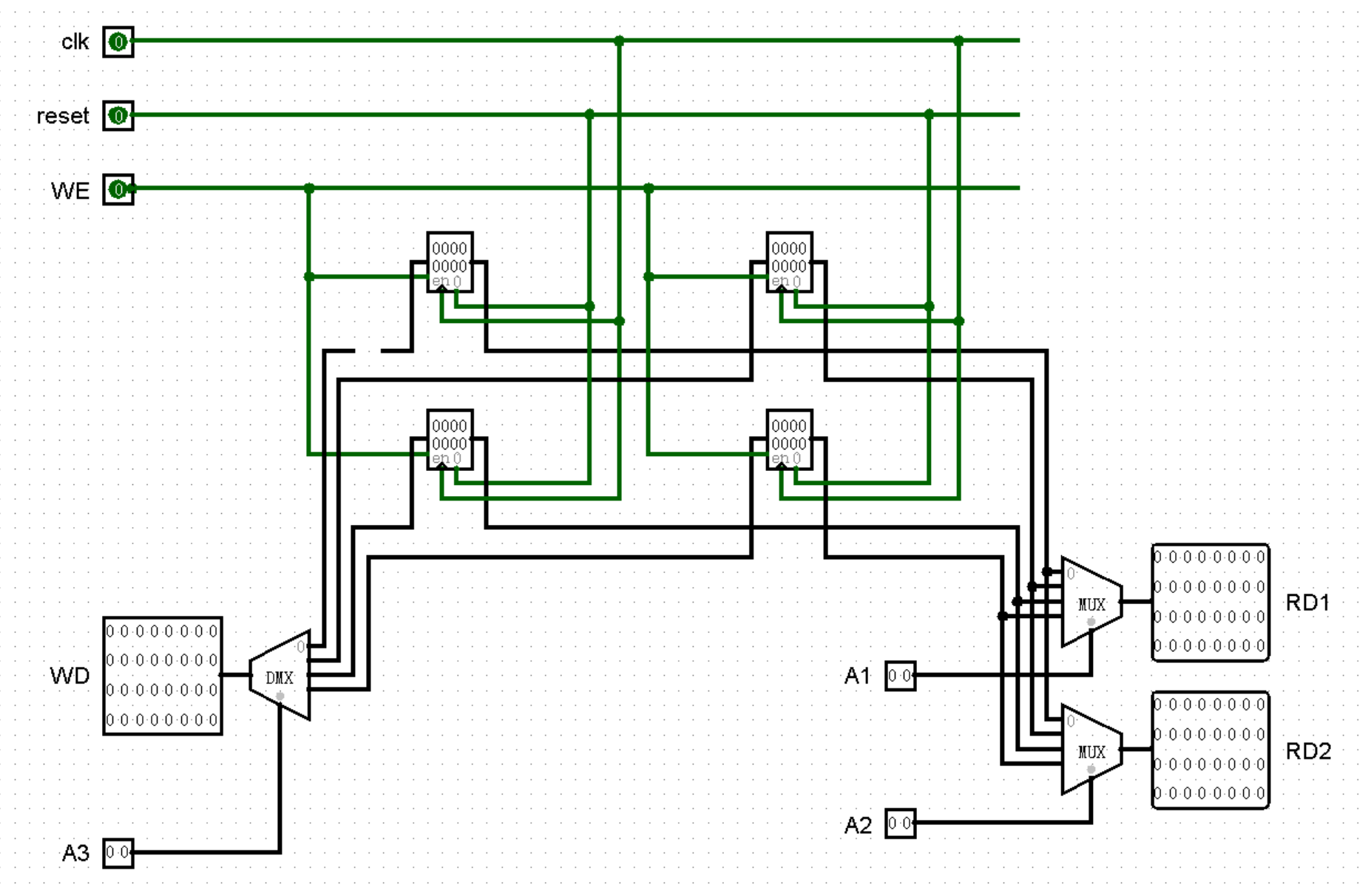
这里有一些小细节,所以我们在这里停顿。最明显的应该就是那根断掉的导线了,这可不是图片加载错误,是因为 0 号寄存器是不能被赋值的,所以我故意掐断了这根导线(笑)。
接下来还有一个细节,在图片中完全体现不出来,但是如果你是我的忠实读者,应该能想起一个非常非常遥远的 callback ,那就是要将 DMX 元件的 Three-state? 属性改为 Yes 。这个知识点在第一章我们初次遇见 DMX 元件的时候就强调过,这里再次提醒一下:DMX 元件在默认情况下,除了 A3 对应端口的输出值为 WD 的值之外,其余所有端口的输出值都为 0 。也就是说,每当时钟上升沿到来时,除了 A3 对应的寄存器会被赋值为 WD 以外,其余所有寄存器都会被赋值为 0 !这显然是错误的,好在使用上述解决方法进行操作之后,就可以正常模拟只为一个寄存器赋值的行为了。
这样,我们就完成了 GRF 模块,现在我们稍作修改一下它的外观,将它添加至主模块中:
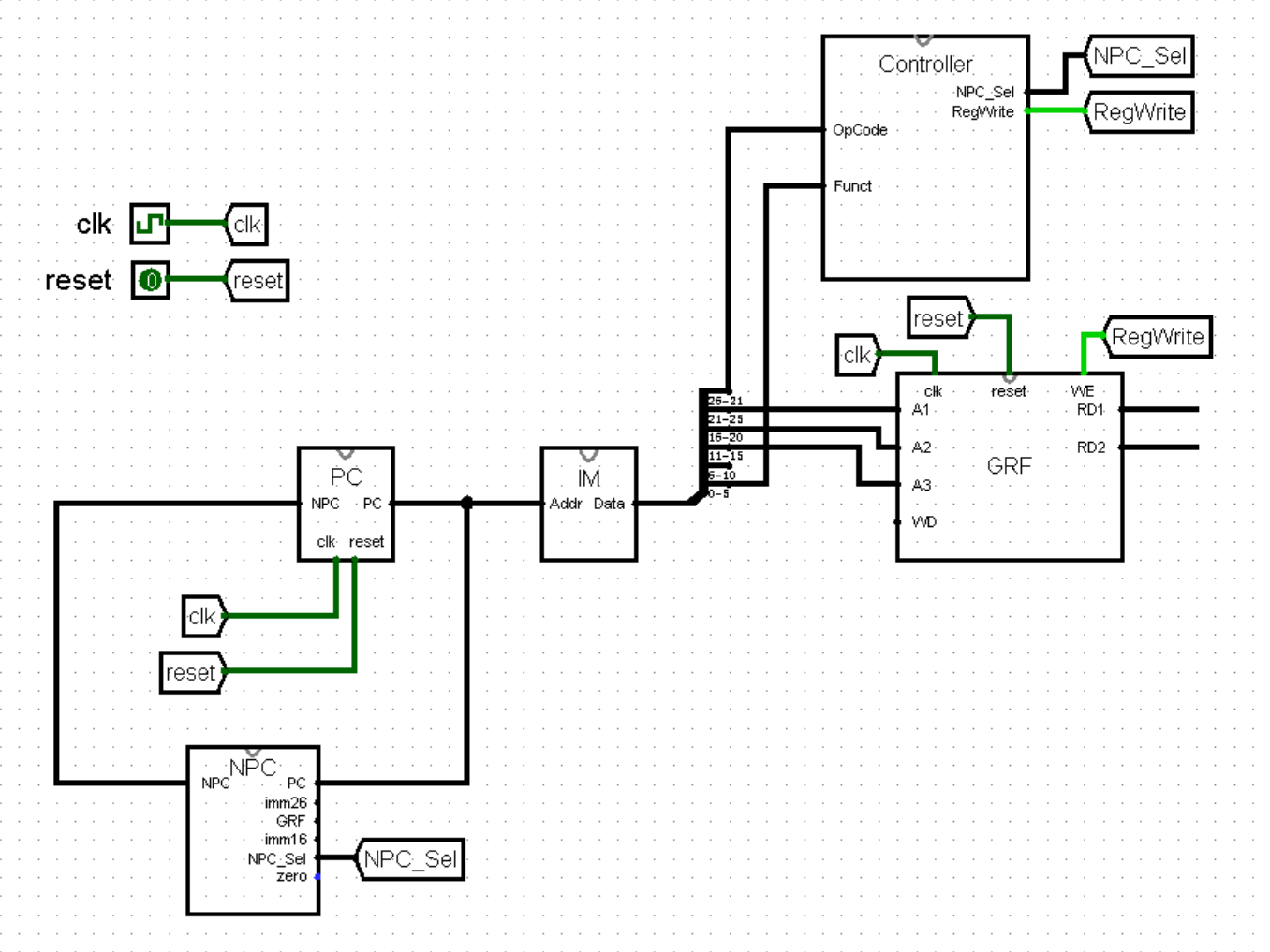
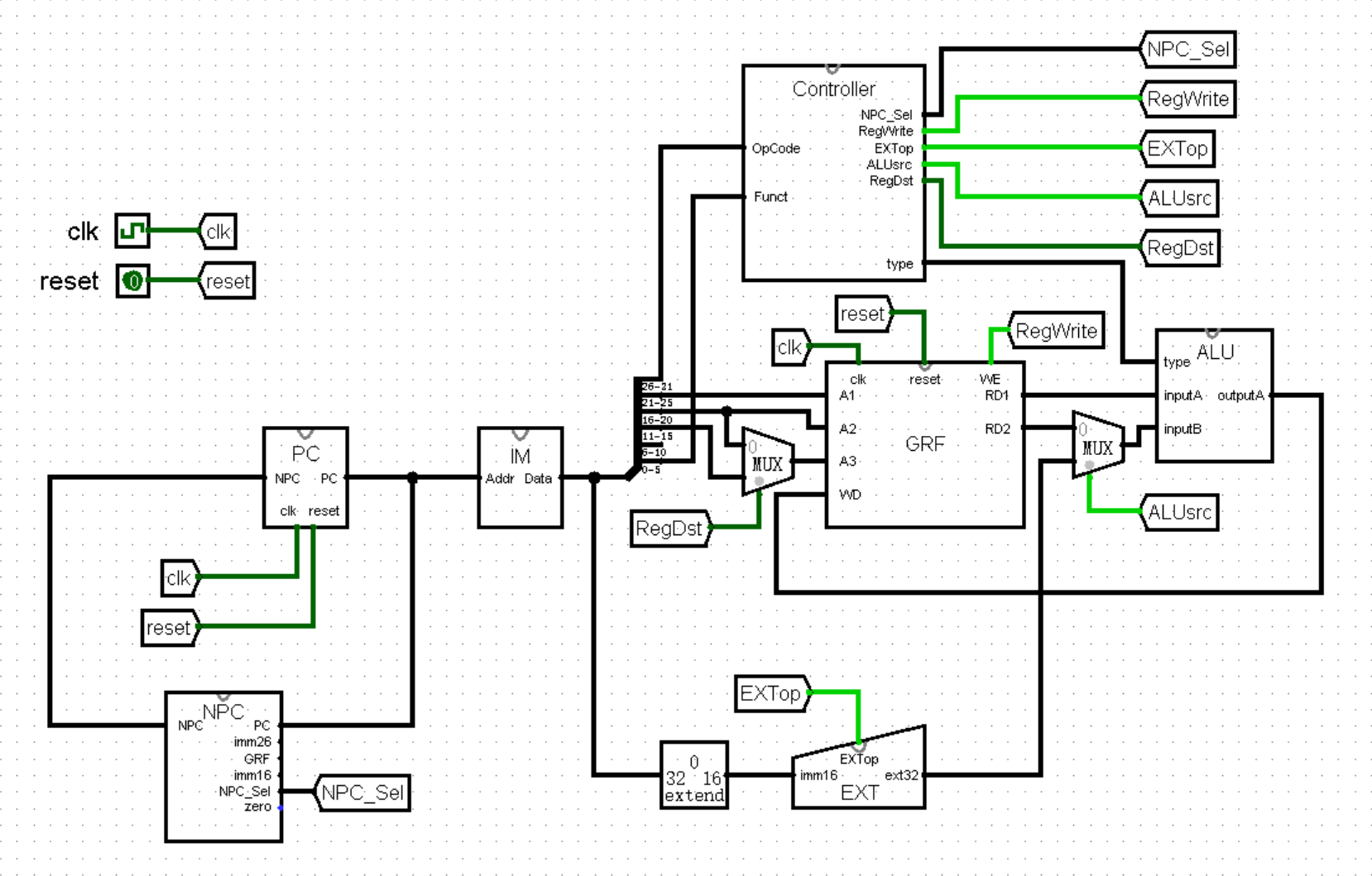
这里我们将指令的拆分进一步细化,按照 R 型指令分为了 OpCode 、rs 、rt 、rd 、shamt 和 Funct 六个部分;同时在 Controller 中加入了 GRF 写使能端的对应接口 RegWrite ,如下图所示。其中 0 表示指令执行过程中不会写寄存器,1 表示指令执行过程中会写寄存器:
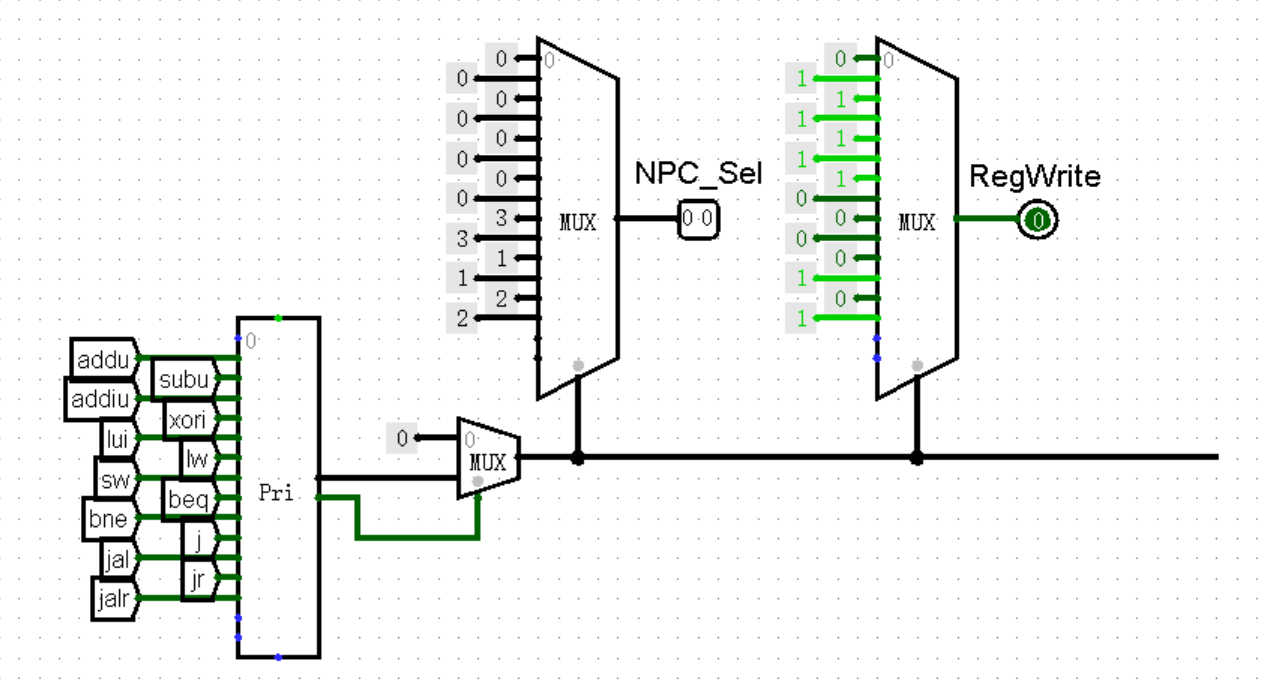
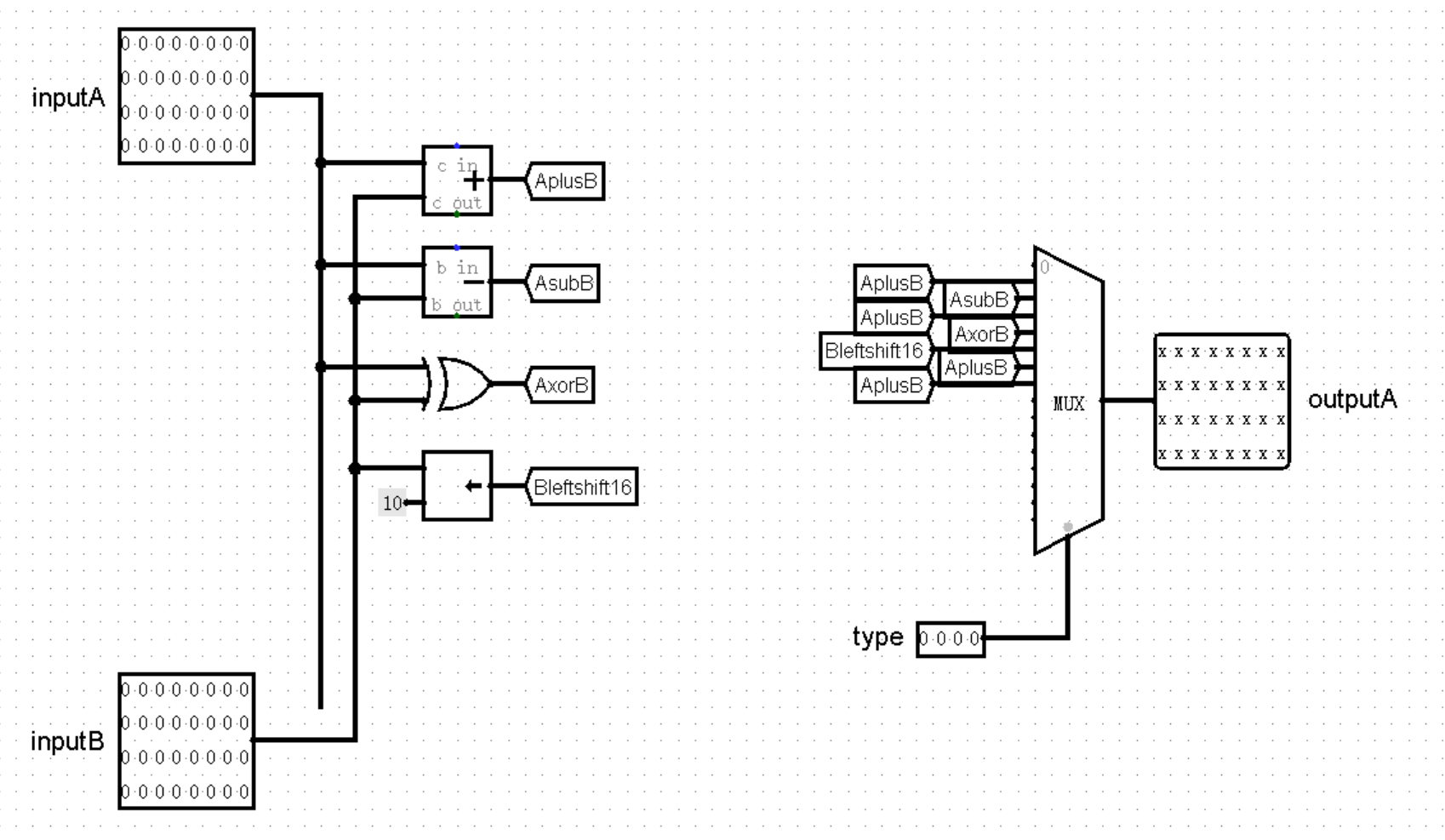
到目前为止,我们已经几乎完成了 R 型计算类指令三个步骤中的第 1 步和第 3 步,接下来我们来完成第 2 步,也就是对 GRF 输出的 RD1 和 RD2 进行运算,再将结果输入回 WD 中。
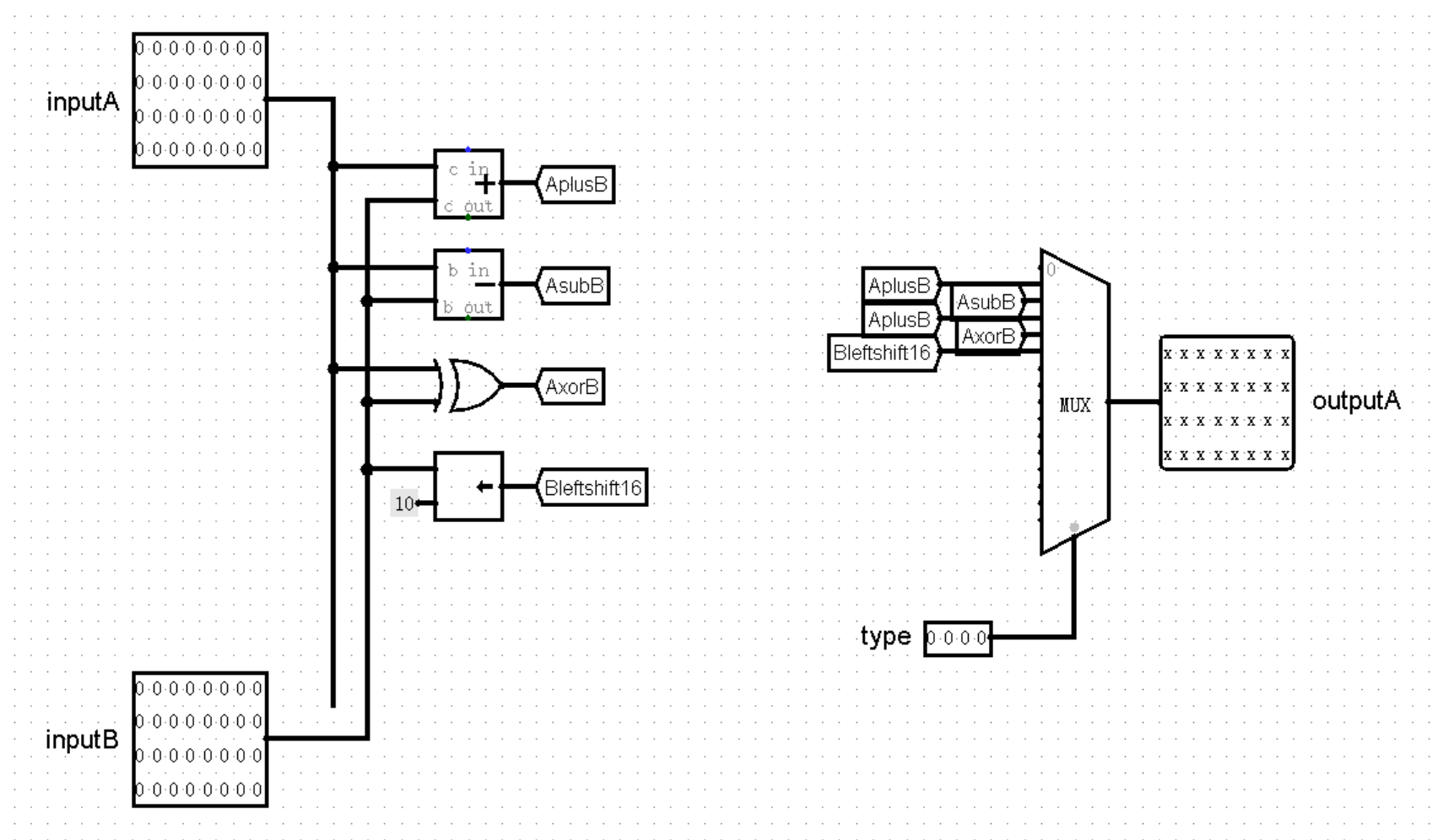
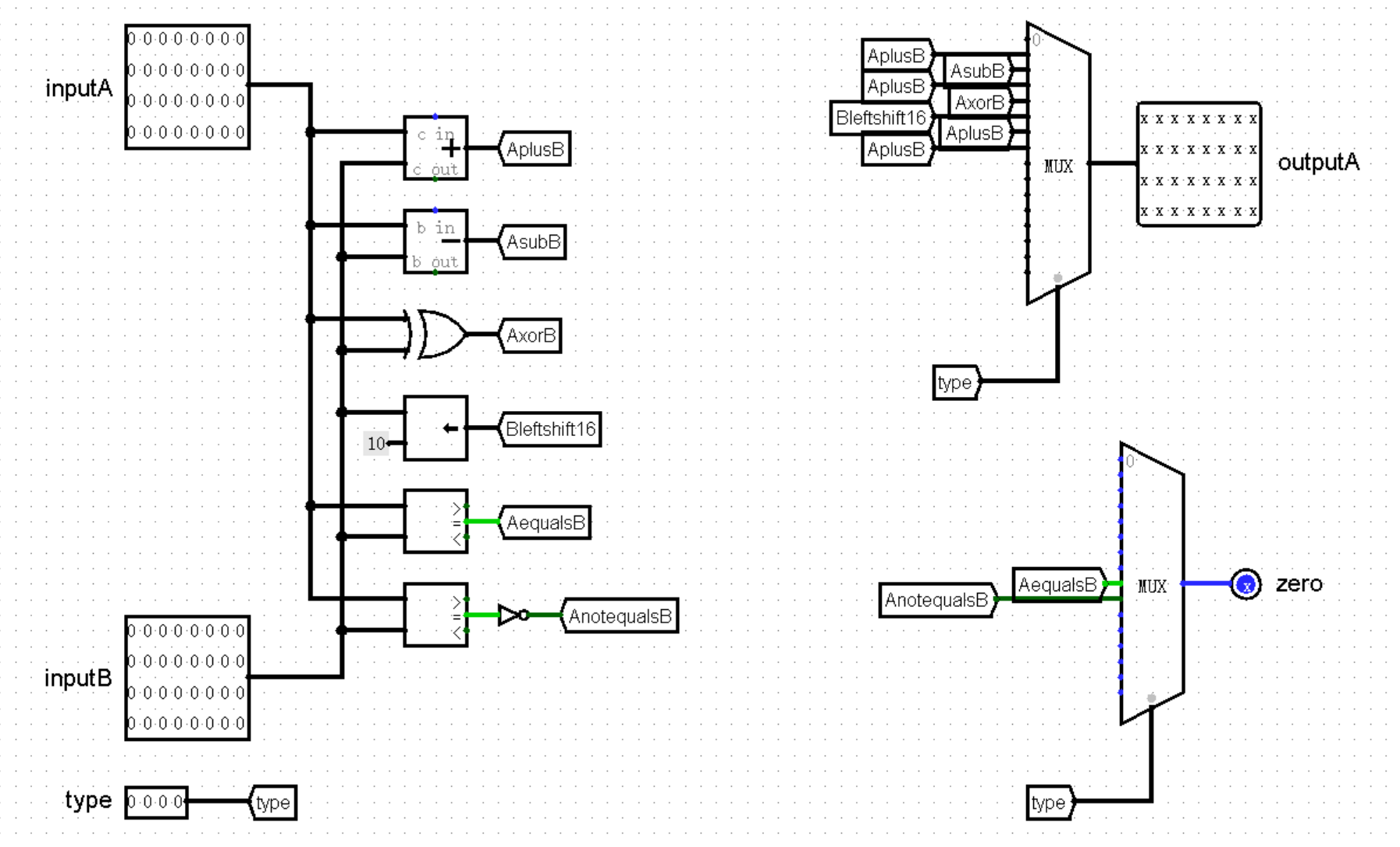
不过我们知道,R 型计算类指令的种数相当之多(虽然我们目前并不会实现这么多),直接在主模块中计算的话,电路图就会变得非常杂乱,不如我们再创建一个模块,专门进行这项运算的工作,于是我们又发明了 ALU 模块!
ALU 模块的任务很简单,输入两个值 inputA 和 inputB ,根据指令的类型进行不同的运算,输出一个结果 outputA 。说起来恐怕也就只有一个问题,我们应该如何或许指令的类型呢?当然还要得益于神通广大的 Controller 了!当然了,如果将十几个独热码全部作为 Controller 的输出端口,那可能有点太复杂了,不过我们早已经使用优先编码器把这些独热码转换为了数字,只需要让 Controller 直接输出这些数字,再由 ALU 作为输入就可以了:
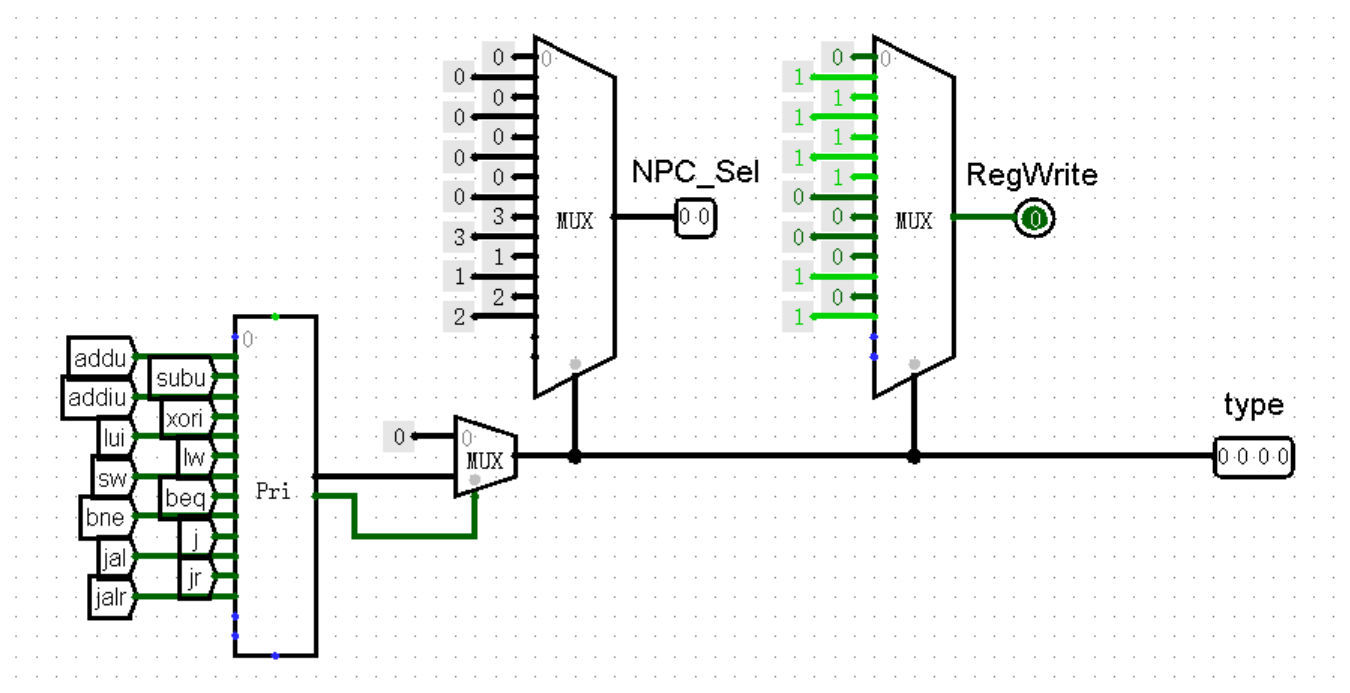
有了 type ,我们在编写 ALU 的路上就畅通无阻了,只需要注意将指令种类和代表它们的数字严格对应上就可以了:
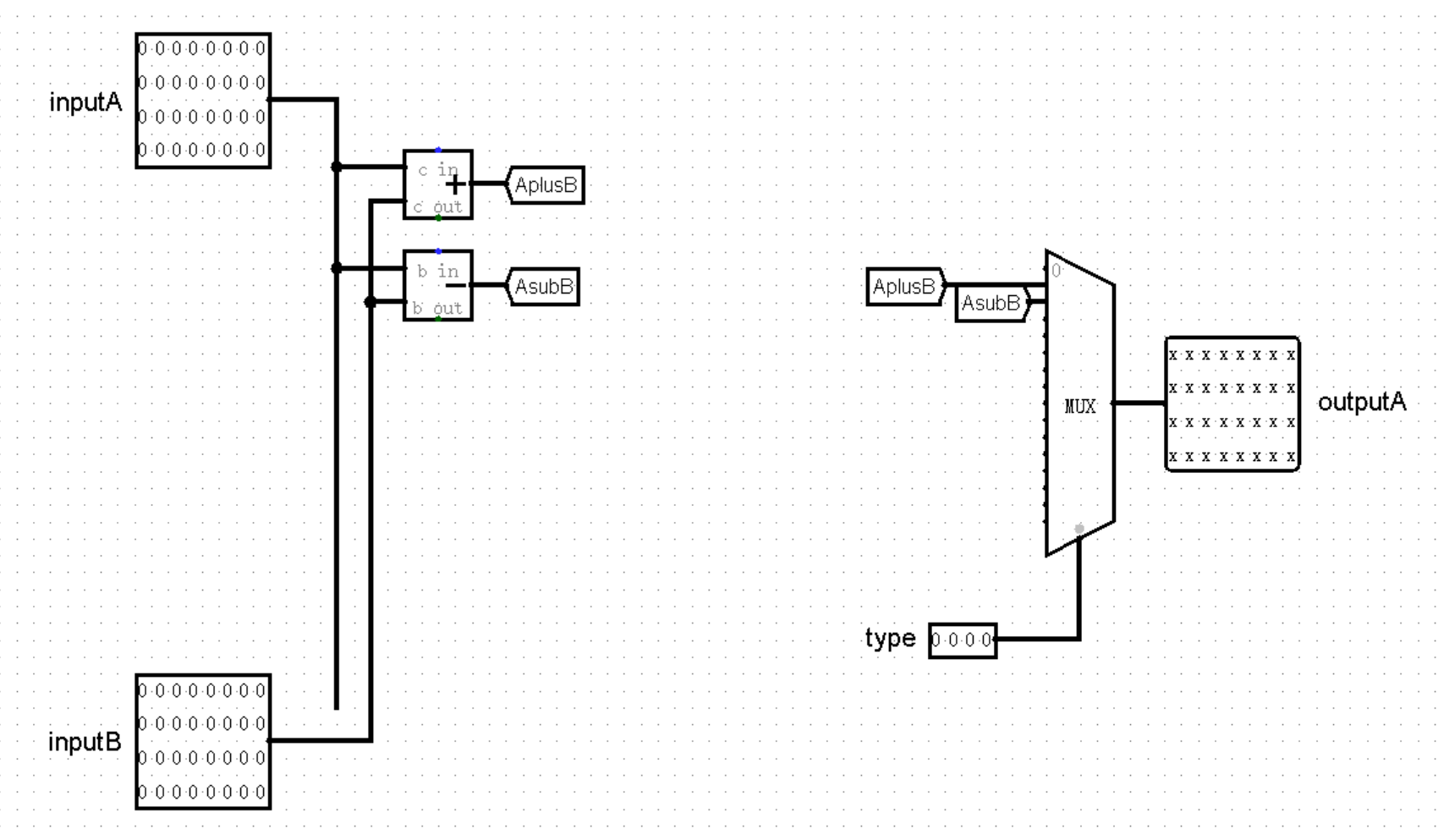
(这里当 MUX 的选项为 0 时,因为在 0 号接口没有输入值,所以输出为全 X 。因为 0 号接口对应的指令是 nop 或其它未实现指令,并不会用到 outputA 这个输出值,后续也会有其它指令同样不需要用到这个输出值,例如 beq 等指令,此时输出为全 X 均是正常现象)
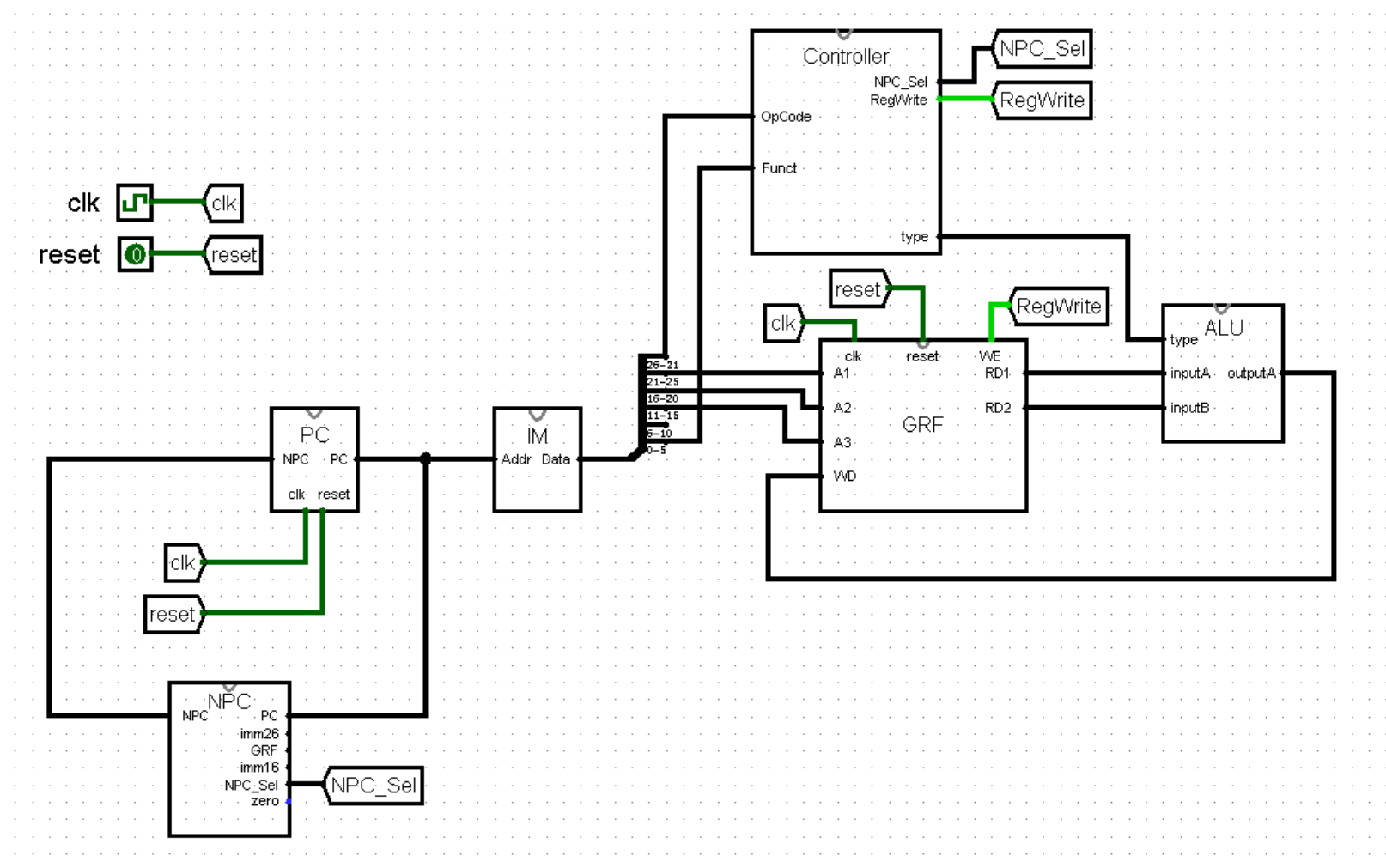
最后,我们修改 ALU 模块的外观,放置在主模块中,连好相应的接口。自此,我们的 CPU 终于能够运行指令了!(虽然算上 nop 也只支持区区 3 条指令,不过万事开头难,还是可喜可贺,可喜可贺!)
【I型计算类指令与EXT模块】
刚刚我们稍微体会了一下旗开得胜的喜悦,让我们继续吧!接下来要添加的 3 条新指令是 addiu xori 和马里奥的兄弟 lui !
我们首先来思考一下这些 I 型计算类指令与刚才实现的 R 型计算类指令有什么区别。一个区别就是 ALU 的输入端 outputA 和 outputB 不再是源自 GRF 输出的 RD1 和 RD2 ,而是 RD1 和一个立即数;另外一个区别则要从指令的结构上看出来了,那就是 I 型指令中要被赋值的寄存器,也就是连接 GRF 模块 A3 接口的寄存器,不再是 rd 寄存器,而是 rt 寄存器。
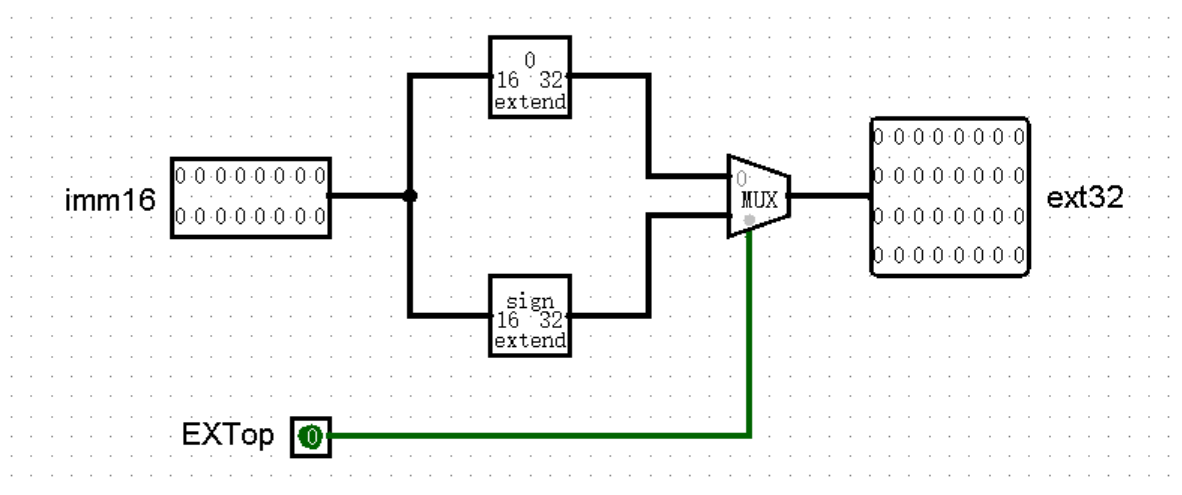
接下来我们来适配一下这两个功能,首先是支持 16 位立即数参与 ALU 计算。看起来只需要将指令的最低 16 位取出来,和 RD2 一起接入 inputB ,再加一个 MUX 元件和 Controller 接口选择即可。不过在此之前我们还是应该注意一下位宽问题,16 位的立即数终究还是和 32 位的 inputB 接口走不到一起,所以我们需要先将 16 位立即数扩展至 32 位。
那这里又有一些说法了,敏锐的你肯定想到了,既然是位扩展,肯定就会有符号扩展和无符号扩展之分。非常巧合的是,我们要新加的 3 个指令里,addiu 指令是符号扩展,xori 指令是无符号扩展,而 lui 指令则是两种扩展方式都可以!(当然是刻意的游戏设计,笑)
针对两种不同的扩展方式,我们可以将其整合为一个新的 EXT 模块,采用新的 Controller 接口进行选择:
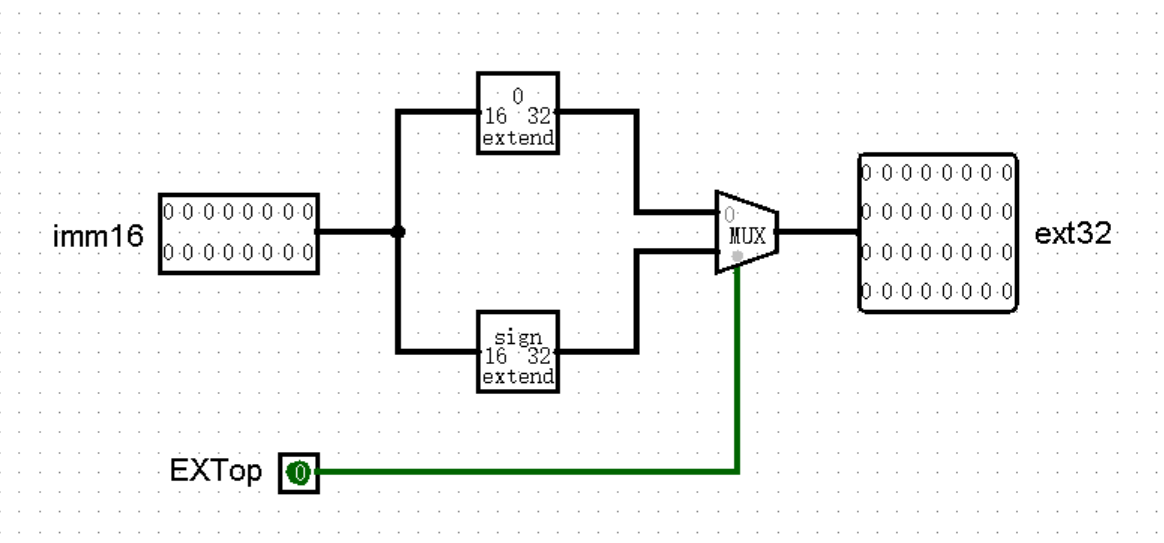
(其实我觉得这个 EXT 模块多少有点鸡肋了,不单独设置一个模块也没什么问题)
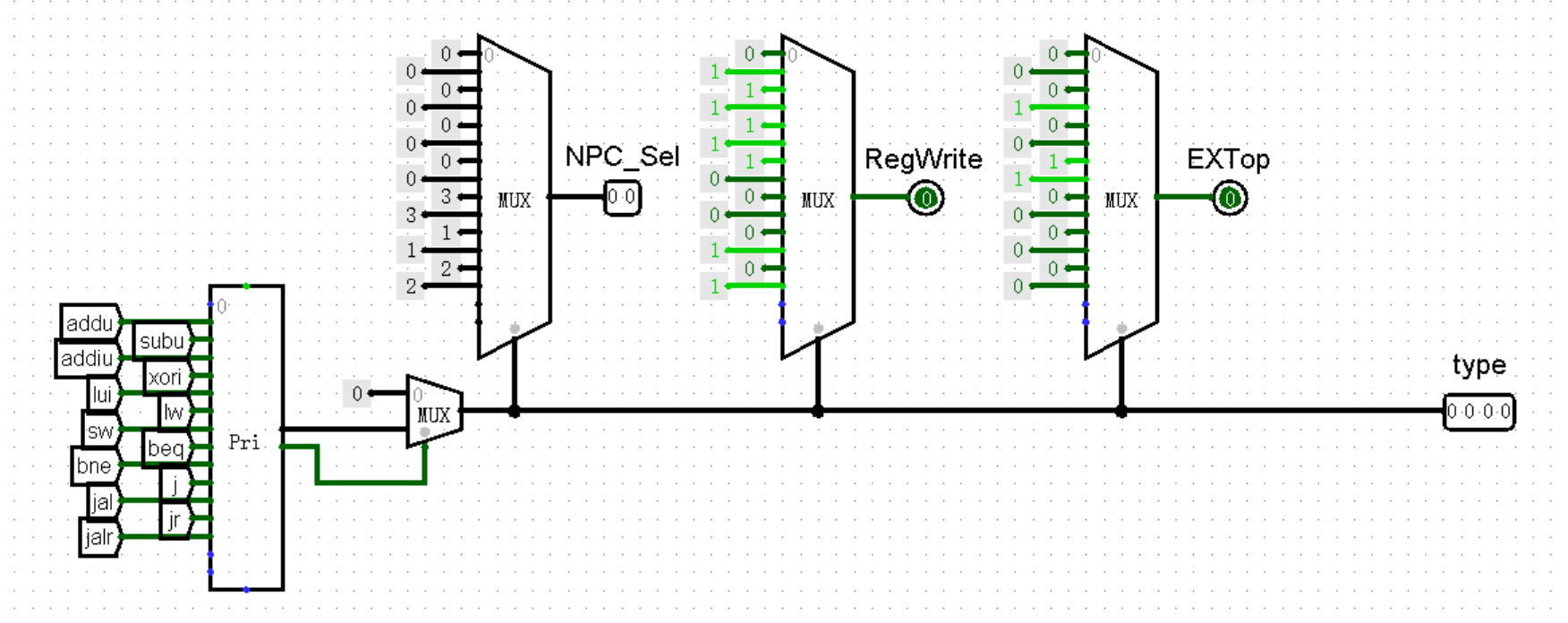
接下来,我们依旧是在 Controller 中增加接口 EXTop :
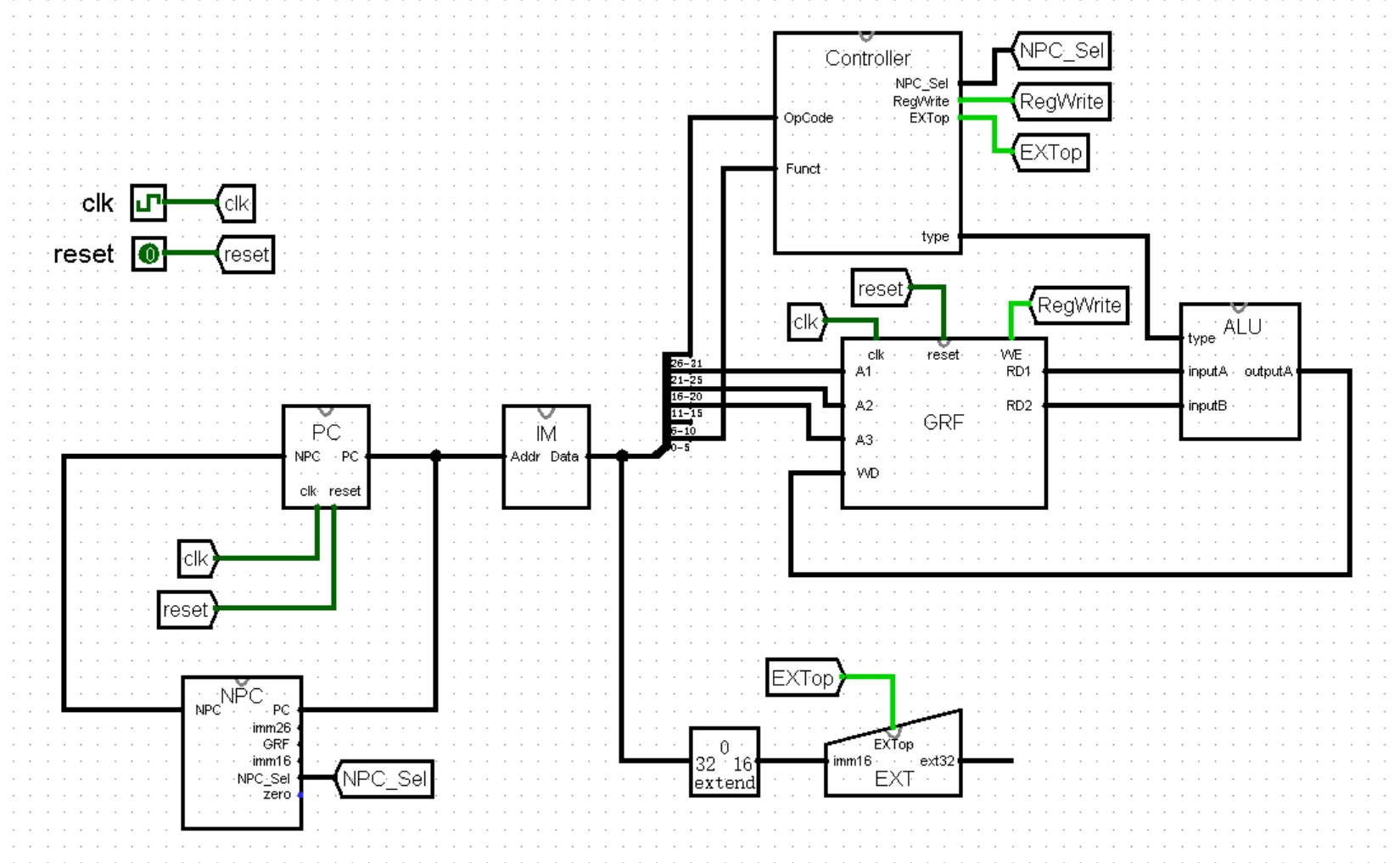
将 EXT 模块放入主模块中:
接下来,为了节省版面,我们一次性完成两个 Controller 接口的添加:一个是控制 ALU 模块的 inputB 端口是接入 GRF 模块的 RD2 端口,还是接入 EXT 模块的 ext32 端口的 ALUsrc ;另外一个是控制 GRF 的 A3 端口是接入指令的 rt 部分,还是 rd 部分的 RegDst 。我们依旧是现在 Controller 模块中进行添加:
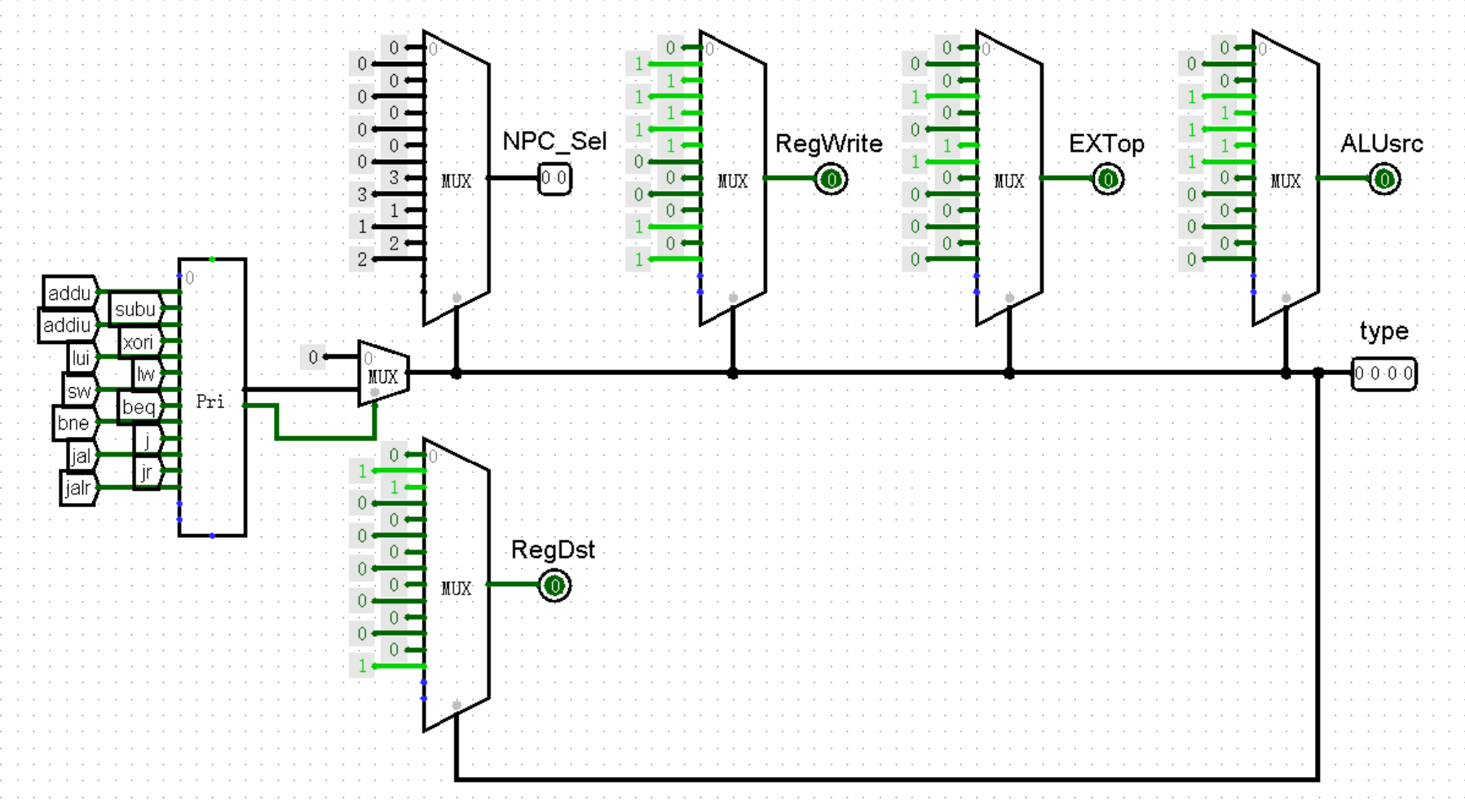
我们在主模块中加入对应的选择:
最后,不要忘了更新 ALU 模块中的计算部分。这里 addu 指令和 addiu 指令的运算是相同的,我们可以在右侧复用这个运算:
这样我们就完成了 I 型计算类指令的追加!在后续的上机考试中,我们也会遇到各种有趣的加指令谜题。虽然谜题千奇百怪,不过只要按照我们刚才加指令的思路去思考,其实也没有看上去那么恐怖嘛!
【内存访存指令与DM模块】
接下来,我们来解决内存访存指令隔壁 lw 和 sw 。不过在此之前,我们需要设计一下内存模块 DM 。
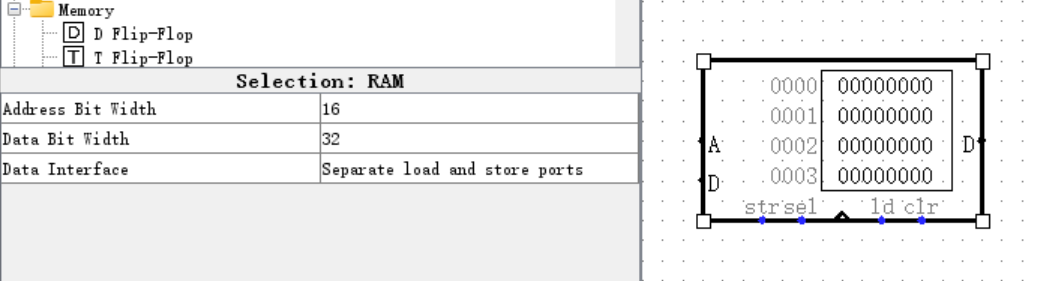
和 IM 模块不同的是,DM 模块不仅要能够读出内存中的内容,还要支持向内存中写入。所以我们采用可读可写的 RAM 元件作为 DM 的主体。仿照 IM 模块中的 ROM 元件,我们将 DM 中的 RAM 元件的地址位宽 Address Bit Width 设置为 16 位,数据位宽 Data Bit Width 设置为 32 位。此外,我们还要按照惯例,将数据接口 Data Interface 设置为 Separate load and store ports :
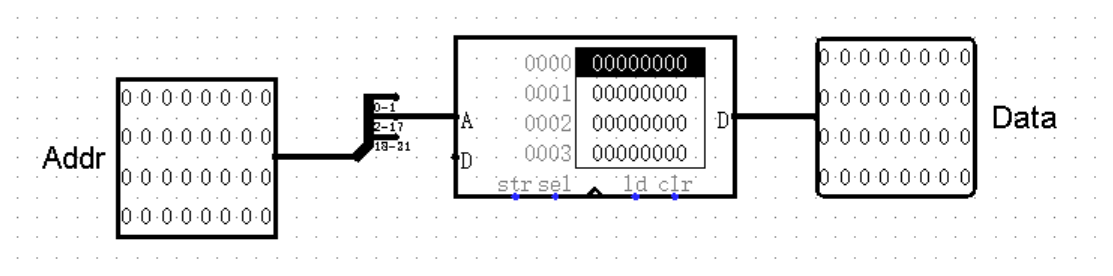
首先,我们模仿 IM 模块,完成 DM 模块的读内存功能。因为在对内存进行访存的时候,我们的首地址不是 0x3000 而是 0x0000 ,所以自然也不需要在 DM 模块中将地址 -3000 ,而是直接右移两位就可以了:
当然,只有读取作用的 DM 模块实在是太逊了,我们还要为它加上写入的功能,这就需要我们加上一堆接口,例如要写入的数据 WD ,以及时钟接口 clk 、复位接口 reset 。当然了,我们不能忘了写使能接口 WE ,毕竟不是所有的指令都有写内存的需求,在绝大多数指令的情况下,我们需要保证写使能是关闭的,防止将一些不正确的数据不小心漏进内存中:
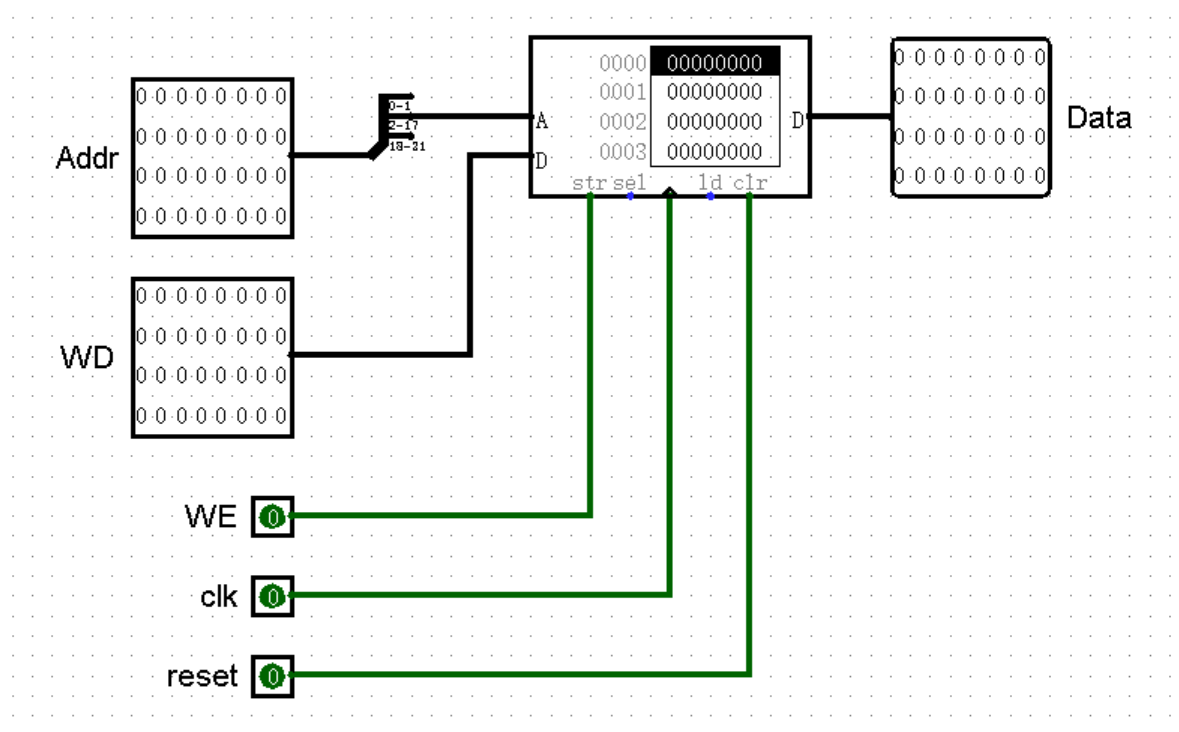
接下来,我们还是为 DM 模块设置好外观,加入主模块中:
接下来我们考虑一下 DM 模块中 Data WD WE 接口该如何连接。
首先是 Data 接口。我们从内存中取出数据,是为了将其写入寄存器中,所以我们将 Data 接口与 GRF 模块的 WD 接口连接在一起。不过这个接口貌似已经有线路了,所以我们需要加入一个新的选择信号 MemtoReg 进行选择。
接下来是 WD 接口。我们将要输入内存中的数据来自哪里呢?在目前我们将要实现指令里,只有 sw 指令需要写内存,而它要写入的数据则来自 rt 寄存器中的内容。于是我们从 GRF 模块中的 RD2 端口取出 rt 寄存器中的数据之后,不仅需要将其传入 ALU 模块,还需要同时接入 DM 模块的 WD 接口。
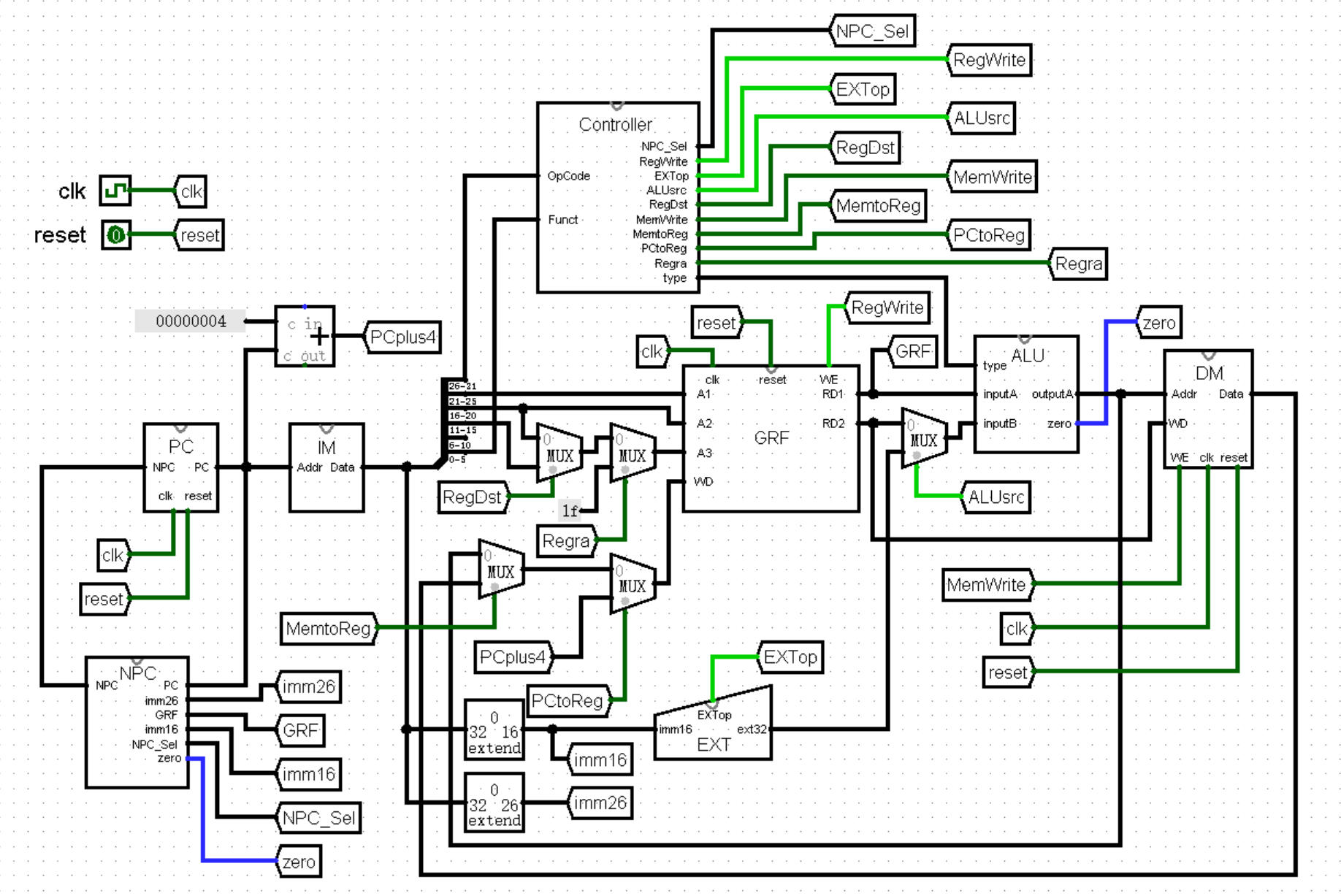
最后是 WE 接口,它的值当然就要来自 Controller 模块了!于是,我们可以画出新的主模块电路图:
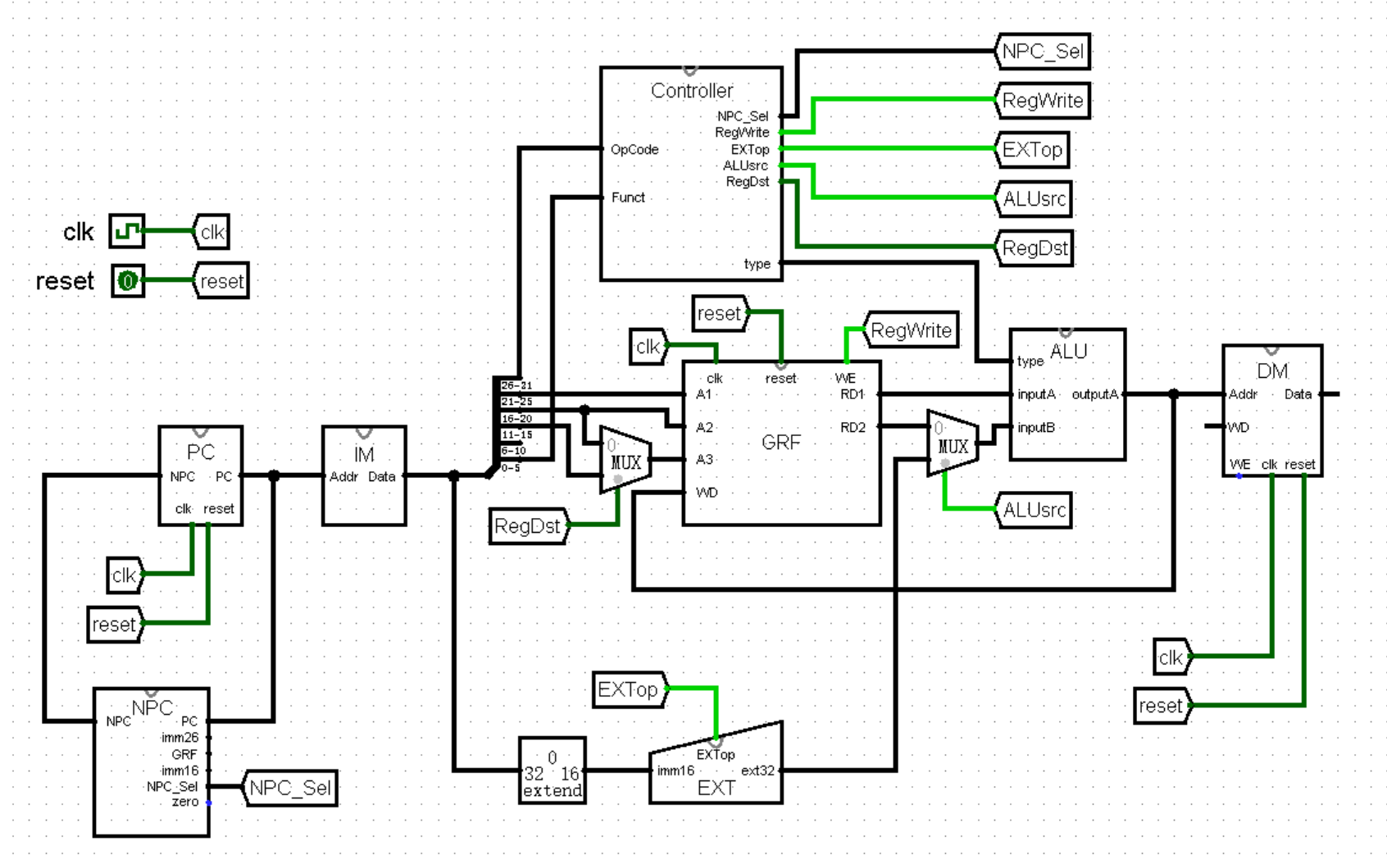
接下来的操作也不必多说了,想必聪明的你已经轻车熟路了!那就是在 Controller 模块中增加接口:
以及在 ALU 模块中增加相应的计算:
这样,我们就完成了内存访存指令 lw 和 sw :
到目前为止,我们已经完成了单周期 CPU 中的所有模块。在接下来加指令的练习中,我们只需要复刻一下之前已经操作过很多次的流程即可。我们可以简单复习一下,大概就是:分析指令的数据通路 -> 增加新的数据通路和选择信号 -> 在 Controller 模块中修改选择信号 -> 在 ALU 模块中加入新的计算。这样,我们就完成了加指令的全部流程!
【相对跳转指令】
刚才我们简单梳理了一下加指令的全部流程,现在我们就用跳转指令来练练手吧!
在相对跳转指令这一部分,我们要加入的是 beq 和 bne 两条指令。我们首先来分析一下这两条指令的数据通路,我们首先需要将 rs 和 rt 输入 GRF 模块,取出 GPR[rs] 和 GPR[rt] 两个值,传入 ALU 模块中。
这一步看起来和我们之前实现过的指令没什么区别,真正的区别在 ALU 模块中。我们并不需要 ALU 模块输出计算后的值,而是输出二者是否相等,也就是决定是否进行跳转的 zero 值,我们将其连接到 NPC 模块的 zero 接口上。配合设定好的 NPC_Sel 值,以及传入的 imm16 ,NPC 模块就可以计算出下一个周期要执行的指令的地址,这样我们就完成了这两条指令的执行。
理清思路后,我们就可以开始着手修改 Controller 模块和 ALU 模块,以及主模块中的数据通路了!
正常加指令的情况下,我们需要在 Controller 模块中加入对新指令 OpCode 和 Funct 的解析,以及为新指令适配已经加入的选择信号。不过这些工作我们在之前已经顺带做过了,而且这两条指令也没有加入新的选择信号,这里就略过修改 Controller 模块这个环节了。
接下来,我们修改 ALU 模块,为其增加新的 zero 接口:
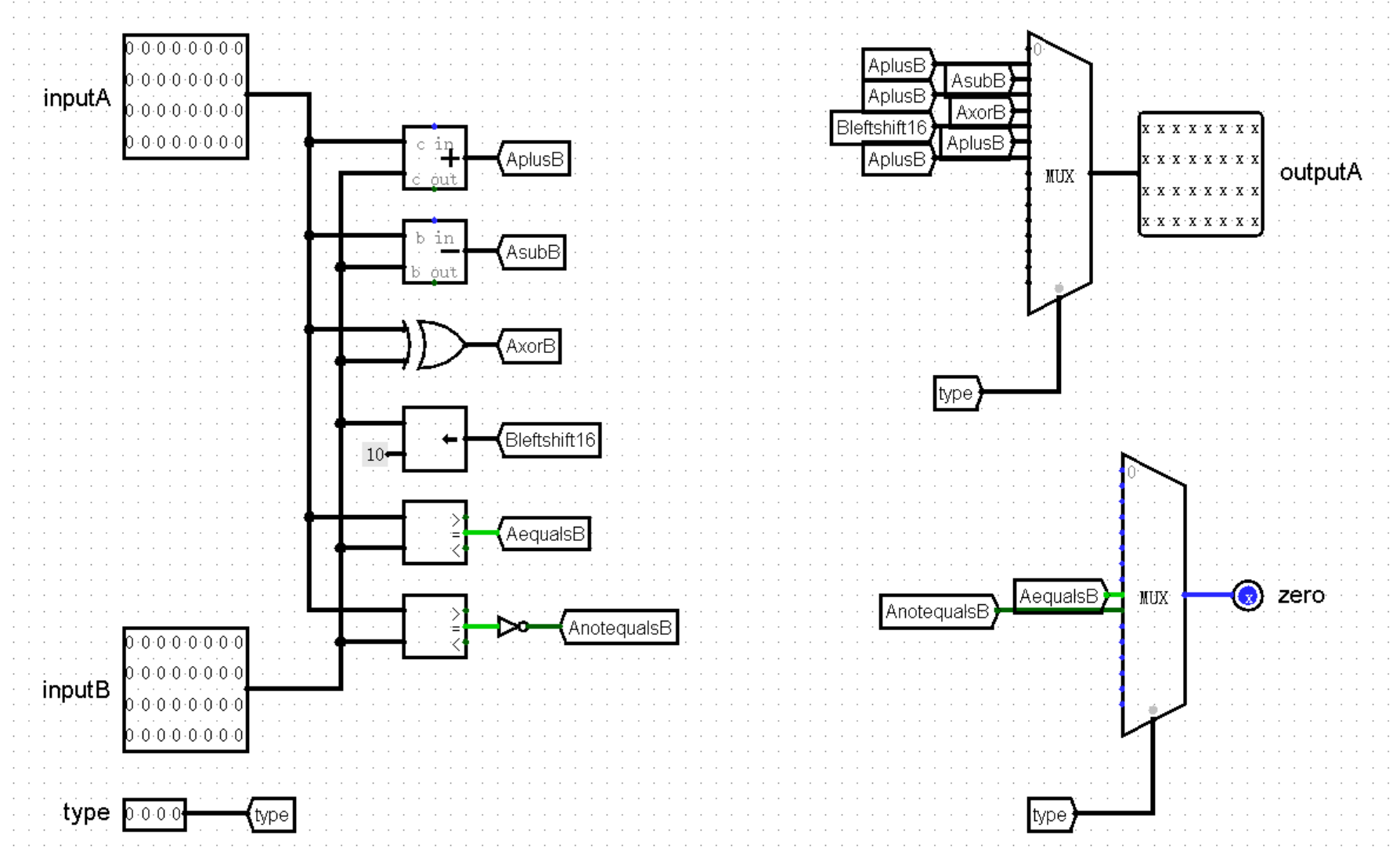
最后,我们在主模块中连接 zero 接口的两端,并向 NPC 模块传入 imm16 ,就完成了 beq 和 bne 两条指令:
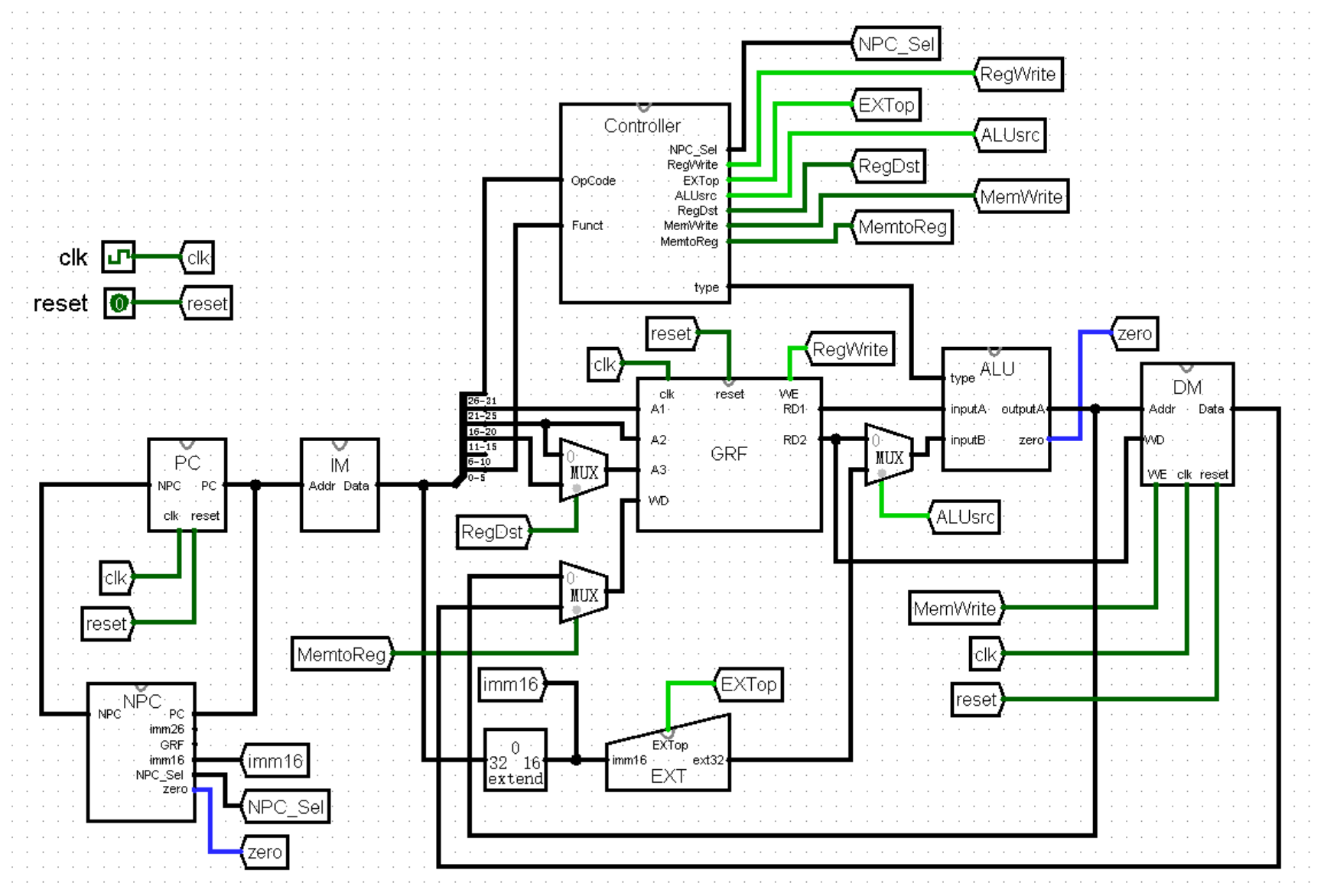
就这么简单?就这么简单!有没有稍微感觉到,其实 CPU 并没有我们想象中的那么难?(笑)
【绝对跳转指令】
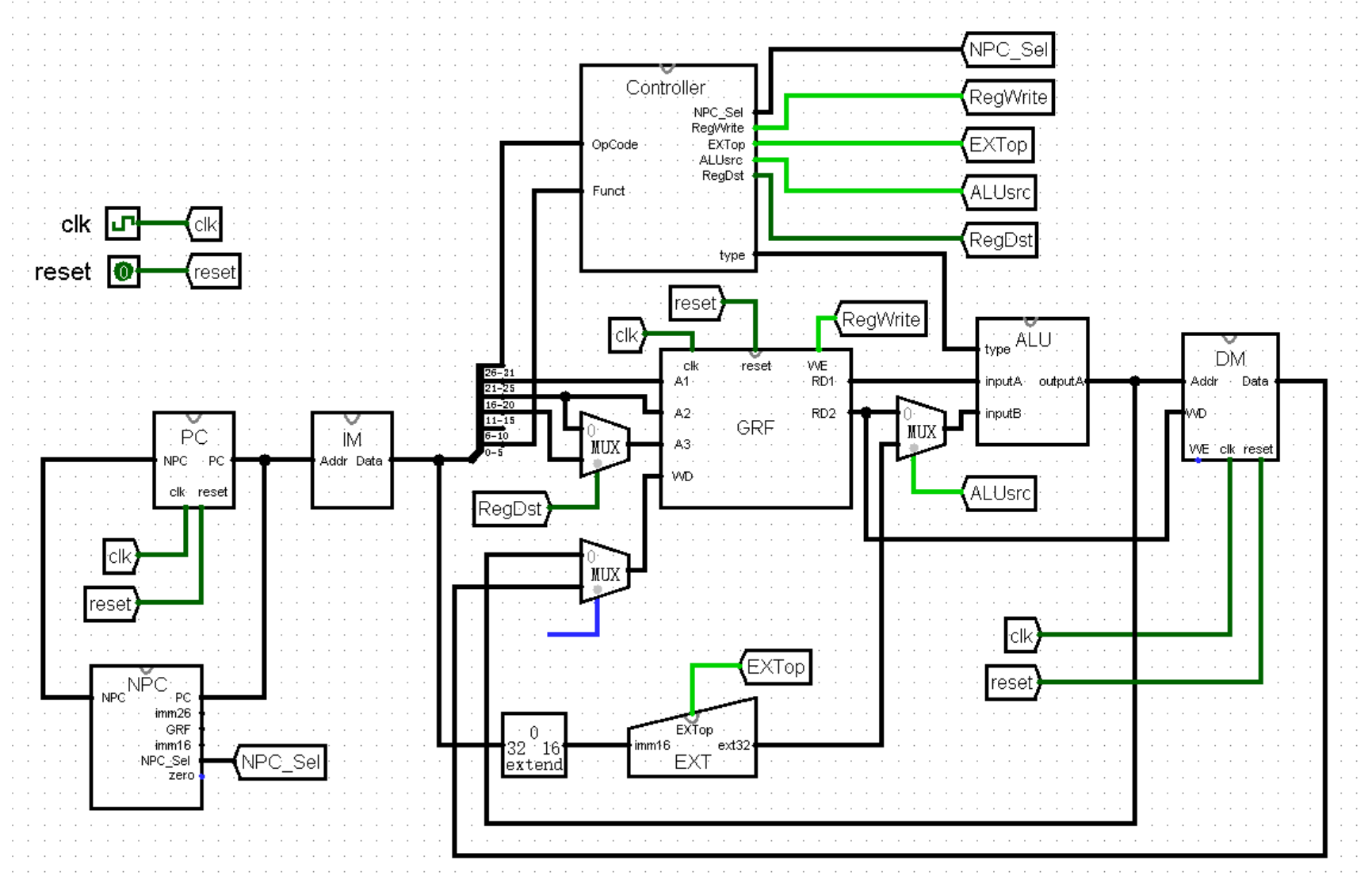
接下来,我们再挑战一下适配四条绝对跳转指令 j jr jal jalr 。相信刚刚速通了相对跳转指令的你现在一定是满怀信心,跃跃欲试了吧!
我们先速通一下 j 指令和 jr 指令。这两条指令不需要读写寄存器,不需要计算,不需要读写内存,真的是什么都不需要!我们已经保证了 Controller 模块能够解析这两条指令,NPC_Sel 接口额输出的值正确,GRF 模块和 DM 模块的写使能关闭,现在只需要将 NPC 的 imm26 和 GRF 两个接口连好,就直接实现了这两条指令:
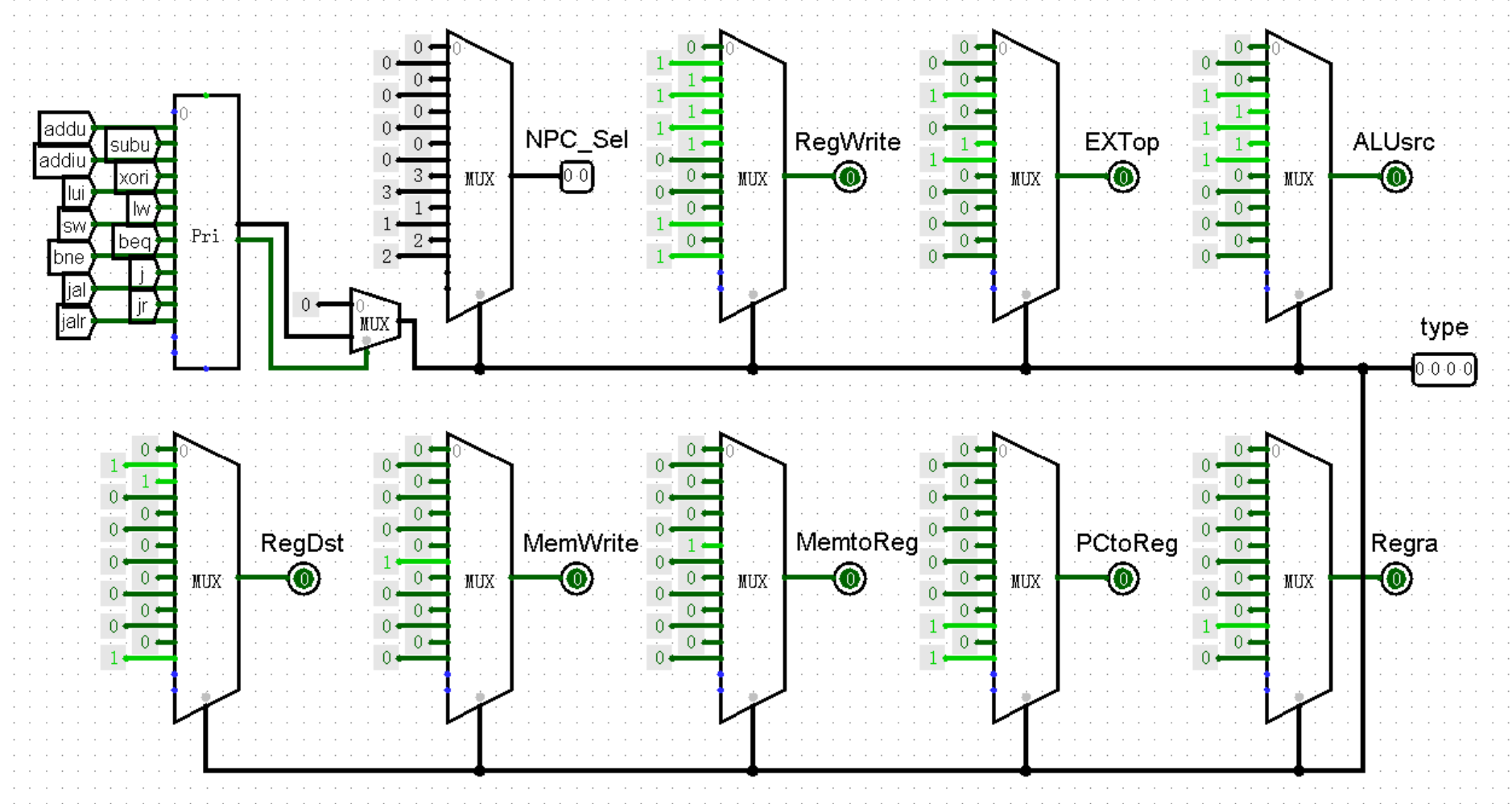
接下来我们来重点关注一下 jal 和 jalr 这两条指令。我们首先来看 jal 指令,它其实就是在 j 指令的基础上增加了“将 PC + 4 写入 31 号寄存器中”这条规则。然而我们仔细分析一下就会发现,无论是将 PC + 4 输入 GRF 模块的 WD 接口,还是将 31 输入 GRF 模块的 A3 接口,都需要我们新开一个选择信号才能实现。不过,我相信以我们现在实力,拿下 jal 这个麻烦鬼也依然是游刃有余!
于是,我们在 Controller 模块中编写接口,PCtoReg 接口负责选择 PC + 4 传入 GRF 模块的 WD 接口中;而 Regra 接口负责选择 31 号寄存器作为输入数据的寄存器:
最后,我们在主模块中连接好全部的选择信号,于是我们就完成了 jal 这条指令:
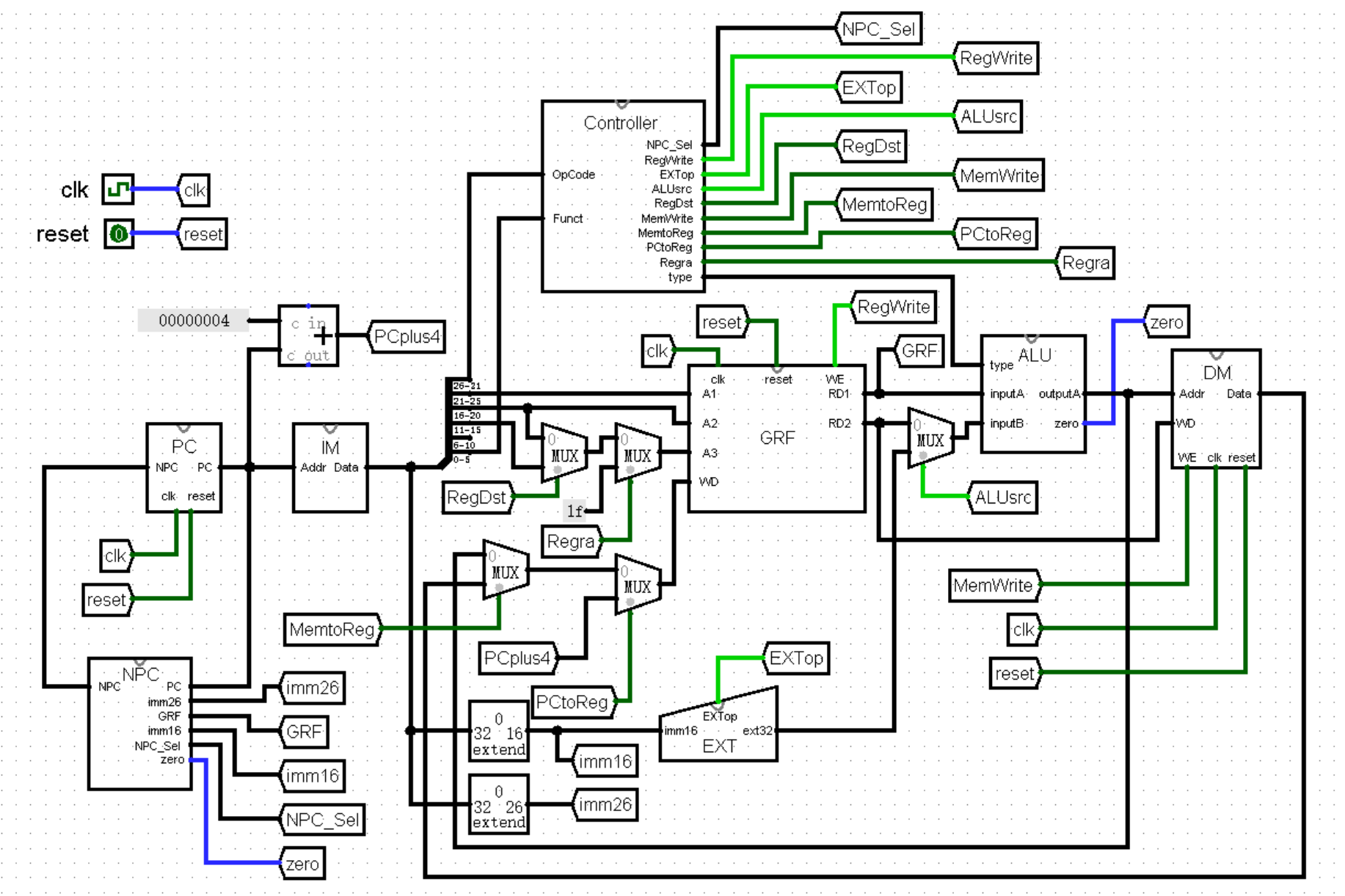
(为了能在 133% 的画面比例下画出 CPU ,真的是把画面运用到极限了(晕倒)我确信有一种优美的画法,但是画面太小,我画不下)
至于 jalr 指令,它是在 jr 指令的基础上加上了“将 PC + 4 写入 rd 寄存器中”这条规则。我们只需在 Controller 模块中设置好相应的选择信号即可(见上上图)。
至此,我们就完成了一个支持 14 种 MIPS 指令,并可轻松拓展到几乎所有常见 MIPS 指令的 CPU !
CPU 搭完真的很兴奋!我猜你大概率是人生中第一次完成这么复杂的数字电路,真的要好好鼓励一下自己,晚上吃点好的吧!
4.3 使用 Verilog 模拟单周期 CPU
接下来,我们试着把我们刚才设计的 CPU 移植到 Verilog 硬件语言上。在第三章我们就已经了解到了一个观点,那就是 Verilog 硬件语言实际上就是在描述电路。所以我们需要做的,其实只不过是将电路图“翻译”成电路,也是非常简单了!事不宜迟,我们趁热打铁,马上开始吧!
我们对 CPU 的移植,从各个模块开始,最终再将所有模块整合成到主模块中。如果你现在还不是特别清楚 ISE 中工程(.xise 文件)与模块(.v 文件)的区别,那么你可能需要稍作停顿,先到上半本书中复习一下,我在这里等着你~
另外,在 Verilog 版本的 CPU 中,课程组为了简便大家的工作量,对复位问题作出了一些细小的改动,我们也随着课程组的脚步一起来改动一下:首先是复位方式从异步复位改为同步复位,前者在 Logisim 中比较容易实现,而后者在 Verilog 中则更加简单,同时也降低了整个电路的复杂度。此外,课程组还保证了在开始执行指令之前,均会将 reset 接口置 1 一次,于是我们的寄存器就不需要使用 initial 块来进行初始化,而只需要在 always 块中写清楚如何重置就可以了。
首先我们从 PC 模块开始翻译。观察下面的图片,我们要实现的接口有:输入接口 input clk input reset input [31:0] NPC ,输出接口有 output [31:0] PC 。另外,我们还需要实现一个寄存器 reg [31:0] regPC ,初始值为 0x00003000 ,在每个时钟上升沿接受 NPC 作为输入,并输出 PC :
根据上面的条件,身经百炼的你,一定可以非常容易写出相应的对代码:
1 | module PC( |
(这里使用了更适合 Verilog 的为寄存器赋初始值的方法,算是一种信达雅的翻译吧(笑),当然你也可以将 Logisim 中赋初始值的方法直译过来,完全没有问题!)
接下来是 NPC 模块,NPC 模块中没有寄存器,完全是组合逻辑,实在是太爽了:
在组合逻辑的 assign 语句中,我们用三目运算符来代替 MUX 模块,写起来非常方便。在编写代码的过程中,我们可能会遇到很多自行定义的魔数(例如 NPC_Sel 接口的值为 0 、1 、2 、3 时分别表示哪种情况),为了使我们在上机时紧张的环境下看得更加清晰,我们可以采用宏定义或者 parameter 型变量的方法来为魔数取名:
1 | module NPC( |
实现了 PC 和 NPC 两个模块,我们就可以使用 IM 模块取出当前指令了:

不过 Verilog 中并没有提供给我们类似于 ROM 和 RAM 这样的元件,但是好在我们可以通过定义寄存器数组 reg [31:0] ROM [0:4095] 的方法来实现指令的存储(不要在意 4096 这个大小,足够大即可,防止把内存撑爆)。其中 ROM 中的每个 32 位寄存器都存放着一条指令,在读取指令时,我们只需要提供数组的下标,即可取出对应位置的整条指令,其实和 Logisim 中地址转换的逻辑是相同的。
另外,我们还需要通过一些手段,将写有机器码的 txt 文件装载到 ROM 中,这时候我们就可以用到上半本书里提到过的 $readmemh("code.txt", ROM, 0, 4095); 语句了:
1 | module IM( |
然后是巨大的寄存器堆 GRF 模块(大图一个屏幕放不下,还是放 4 个寄存器的小图):
我们依然可以通过定义寄存器数组的方式解决,妈妈再也不用担心我的 GRF 太大画不下了!这里在同步复位的时候用到了最基础的 for 循环,正好我们也来回忆一下 for 循环的写法:
1 | module GRF( |
接下来是短小精悍的 EXT 模块,我们向其输入一个 16 位的立即数,以及 1 位的扩展方式,EXT 模块输出一个扩展后的 32 位数:
这个模块一定远比你之前做过的 Verilog 练习题简单,所以就不多说了,直接上代码:
1 | module EXT( |
接下来是 CPU 的心脏(我自封的)—— ALU 模块:
依旧是组合逻辑,道理很简单,不过由于三目运算符串的结尾必须要有一个类似于 else 或者 default 的内容,所以并不支持直接不定义不会用到的选项,此时我们可以将输出设置为一些特殊值,来表示 CPU 可能出现了 bug ,这里选用的是全 0 :
1 | module ALU( |
再之后是 DM 模块:
我们依旧采用寄存器数组的方式实现 RAM(当然,这里的数组开得也比较小),只需要做一个最简单的寄存器赋值运算即可:
1 | module DM( |
最后就是 CPU 的大脑(依旧是我自封的)—— Controller 模块:
毕竟是组合逻辑,其实难也难不到哪去,不过复杂度上还是有的,写代码的时候还是要格外细心:
1 | module Controller( |
完成了所有的模块之后,我们就需要将所有模块连接在一起,在主模块上完成我们我们最终的成果:
主模块的线路错综复杂,稍有不慎连错一根就可能导致整个 CPU 直接抽疯。而且 Verilog 也不会像 Logisim 一样直观,接错线并不一定会有特别明显的报错,所以我们还是要拿出 120% 的细心,像拆炸弹一样谨小慎微地连接好我们的电路:
1 | module mips( |
至此,我们就将我们的 CPU 成功移植到了 Verilog 上,是不是非常简单?收工收工!
4.4 本章结语:再见,单周期 CPU !
首先还是要恭喜你读到这里,这说明你已经打通了 CPU 的第一关,了解了 CPU 的整体结构和运行逻辑,用两种不同的方法实现了相当复杂的单周期 CPU !
在 Logisim 一节中,我们从实现每条指令的需求出发,设计了一个又一个的模块,了解到如此壮观的 CPU 世界中,每个不起眼的接口、导线都有着不可或缺的意义,等待着执行独属于自己的指令。
在 Verilog 一节中,我们则是按照模块的顺序,将每个模块逐个翻译为 Verilog 语言。这一节并没有写太多,大多数时间都只是在贴代码,不过我觉得这一节的内容确实也不是很难,因为基本没有涉及到任何新知识点,所以也确实没什么可讲的(其实甚至本来并没打算写这节)。如果你在 Verilog 一章的修炼到位的话,这一关确实可以速通了。
不过还是不要小看了 Verilog !因为在此之后,我们就要离开具象的 Logisim 的怀抱,使用抽象的 Verilog 来完成我们剩下的旅途了!接下来,你将面临的是计组实验课程中的究极大魔王 ——
第五章:五级流水线 CPU
5.1 现在可以公开的情报:一些新的前置知识
【单周期与流水线】
在上一章,我们已经实现了单周期 CPU ;在本章,我们要实现的则是流水线 CPU 。那么,究竟什么是单周期 CPU ,什么是流水线 CPU 呢?
打一个比较简单的比方。Kamonto 每天早上上学之前,需要吃早饭、刷牙、洗脸、洗头发、穿衣服。现在有 100 个这样的 Kamonto 要上学,每个 Kamonto 在完成吃早饭、刷牙、洗脸、洗头发、穿衣服这一整套流程之后,下一个 Kamonto 才可以开始吃早饭,进行自己的流程,这样就需要 100 个周期才能完成任务。这就是我们之前完成的单周期 CPU ,只有当一条指令执行完毕后,下一条指令才能开始执行。
不过,我们可以对 Kamonto 家进行一些适当的改造,将家里改为 5 个不同的分区:吃饭区、刷牙区、洗脸区、洗头区、穿衣区。这样,当每个 Kamonto 吃完早饭,开始刷牙的时候,下一个 Kamonto 就可以进入吃饭区开始吃饭,以此类推,可以实现 5 个 Kamonto 同时进行流程的效果,极大地提升了效率,妈妈再也不用担心 Kamonto 上学迟到了!
这就是五级流水线 CPU 的原理。在后面的实现过程中,我们会将原来的单周期 CPU 分为五个部分,当每条指令执行到第二部分时,就放下一条指令进入第一部分,这样就能够极大地提升指令的运行效率,当然也会极大地提升我们实现的难度(笑)!
【延迟槽】
接下来我们来认识一个新的奇妙装置 —— 延迟槽。我们打开 MARS ,输入如下的 MIPS 汇编指令:
1 | beq $0, $0, branch |
我们观察这段指令,它的执行结果应该如何?当然是 $s0 和 $s1 都没有被赋值,而 $s2 被赋值为 3 了!
接下来,我们选中 Settings 选项中的 Delayed branching ,开启延迟槽,再来执行一下刚才的指令,观察执行结果:
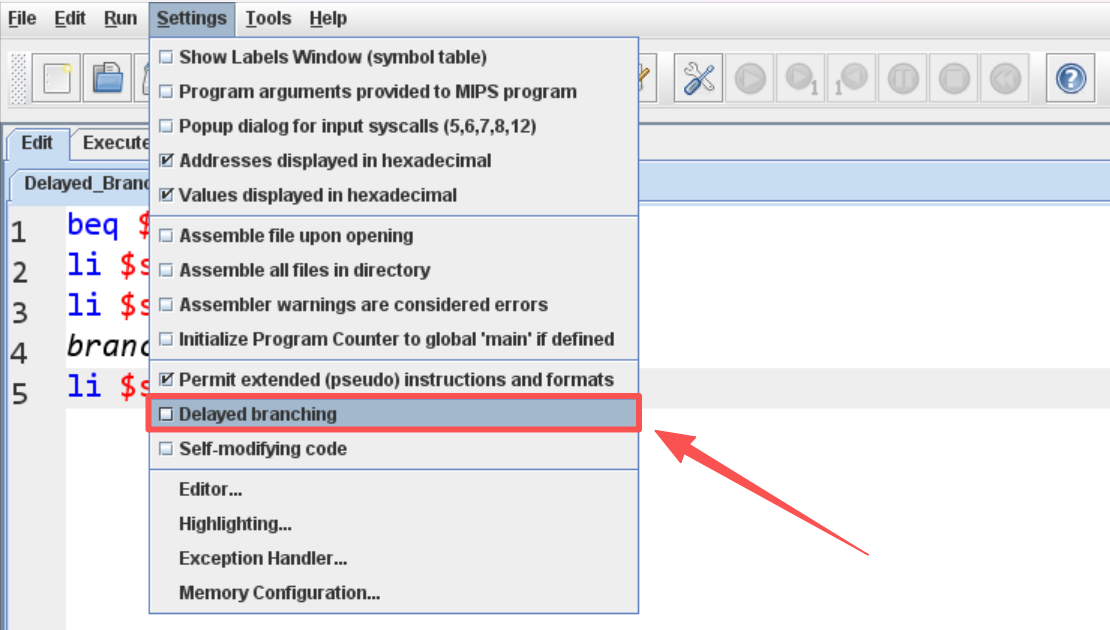
我们在 Execute 界面选择单步执行,会发现在执行完 beq $0, $0, branch 指令后,并没有立即发生跳转,而是进入了下一条指令 li $s0, 1(并且变成了诡异的绿色):
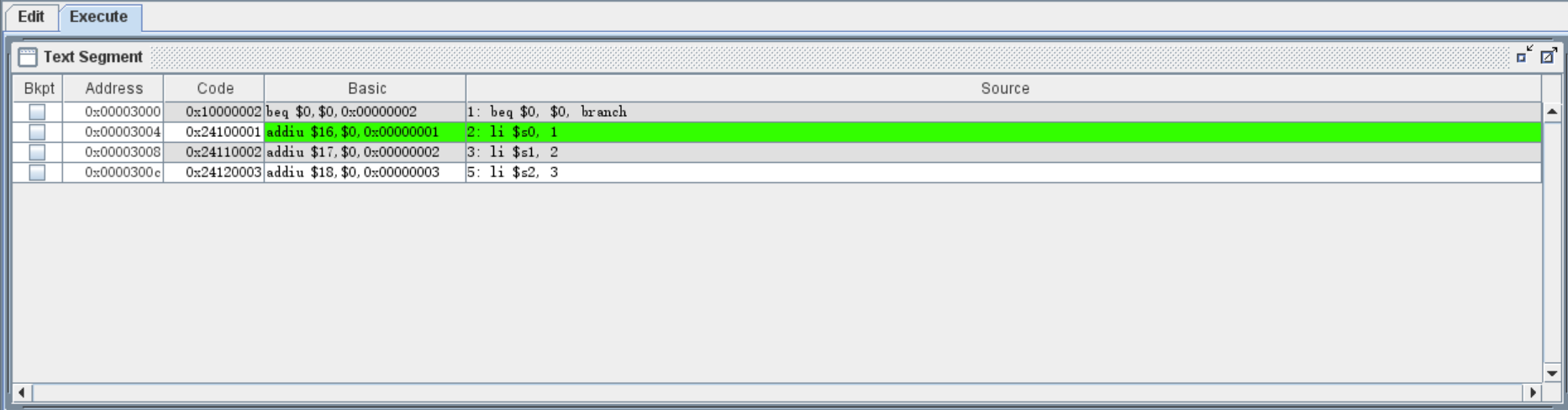
执行完 li $s0, 1 之后,跳转发生,正常进入标签 branch 的位置,执行 li $s2, 3 ,程序结束:
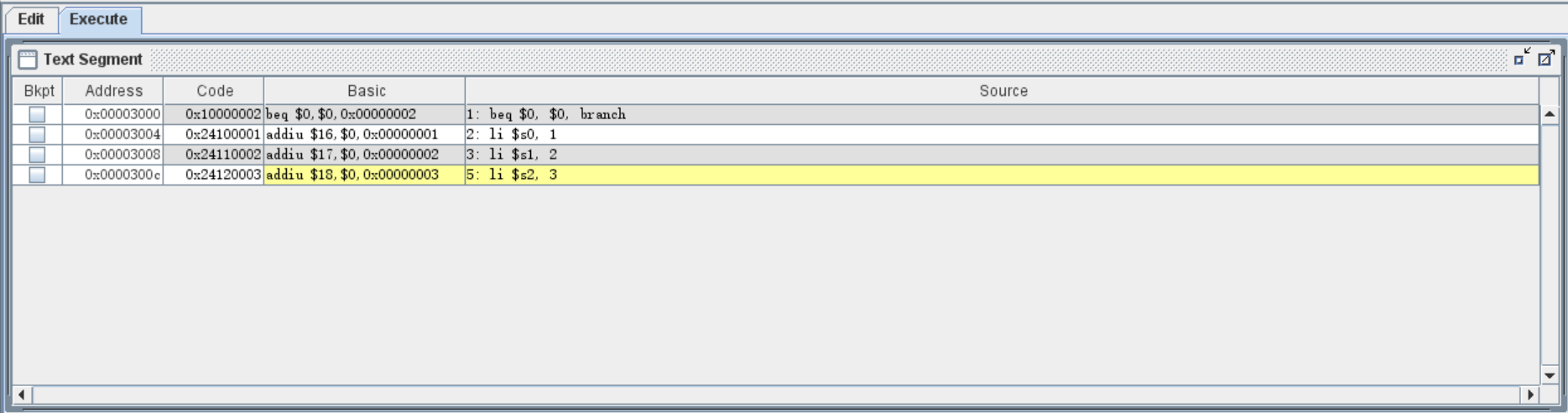
我们从右侧的寄存器值中也可以看出,$s0 和 $s2 分别被赋值为了 1 和 3 ,而 $s1 寄存器没有被赋值:

到这里,聪明的你或许已经猜到了延迟槽的作用了,那就是在跳转发生时不立即跳转,而是先执行跳转指令的下一条指令,随后再“延迟”跳转。
(聪明的我猜到聪明的你肯定会灵机一动问出这样一个问题,那如果跳转指令的下一条指令还是跳转指令,会出现怎样的情况呢?答案是这是一种非法行为,不同的 CPU 得出的结果可能不相同,结果是不可预测的~)
在开启延迟槽时,一些指令的执行逻辑也会发生微妙的变化,这种变化主要体现在 J 型指令中:
首先最明显的就是 jal 指令和 jalr 指令的写寄存器值发生了变化。我们来执行下面一段指令:
1 | jal branch |
运行结果如下:
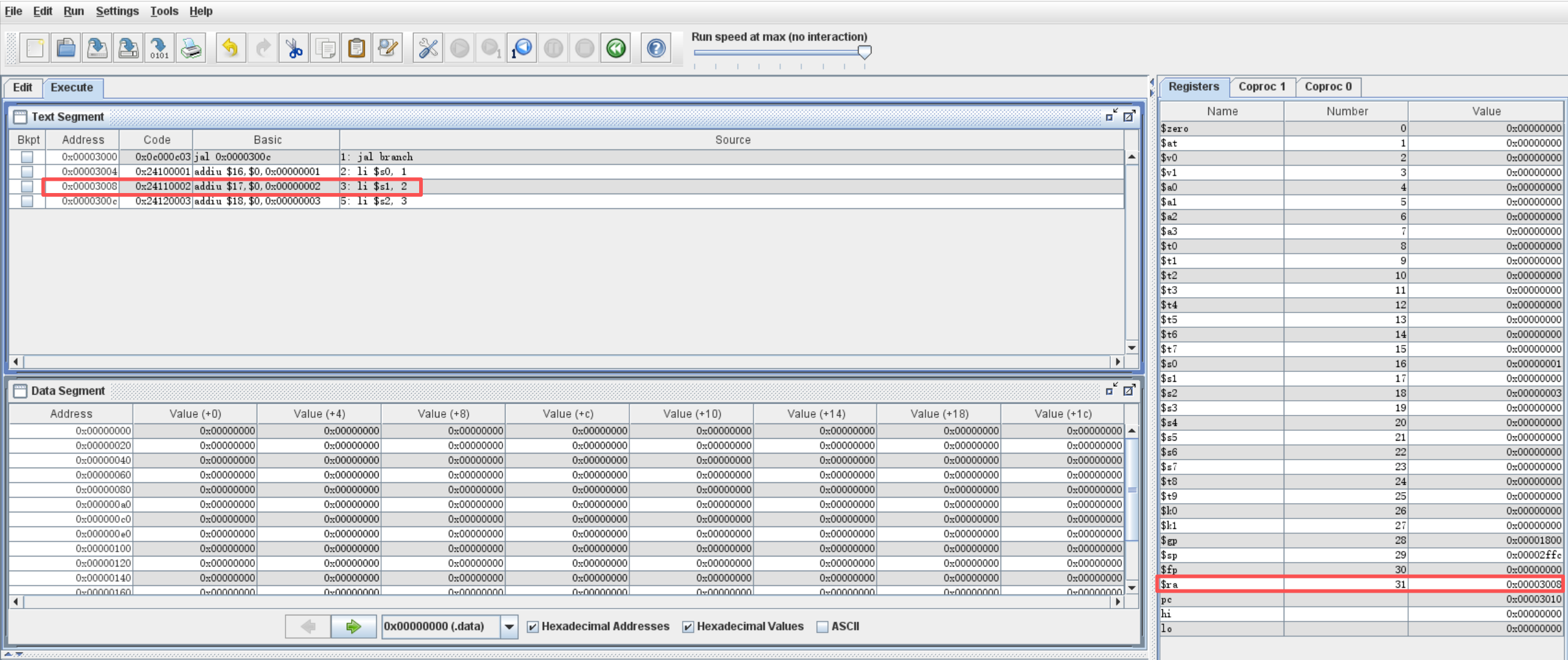
可以看到,此时 $ra 寄存器中写入的地址是 0x00003008 ,并不是 jal 指令的下一条指令的地址,而是下两条指令的地址,其实也就是延迟槽中指令的下一条指令的地址。
其实也很好理解,因为在跳转之前,延迟槽指令已经执行过一次了,我们当然不希望使用 jr 指令返回之后,延迟槽指令再被执行一次,所以当然要从延迟槽指令的下一条指令开始执行了!
接下来还想介绍一个比较隐蔽的变化。我们知道,在 j 指令和 jal 指令跳转地址的计算中,我们需要使用当前 PC 值的最高 4 位进行补位。实际上,我们无论是用什么软件模拟 CPU ,都很难能够达到这么高的指令地址,所以 PC 值的最高 4 位一般总是 0x0 ,不会出现任何问题。
不过,开启延迟槽恰好会导致 PC 值的计算发生非常微小的变化。这个变化需要我们研读 MIPS 英文指令集才能够发现:
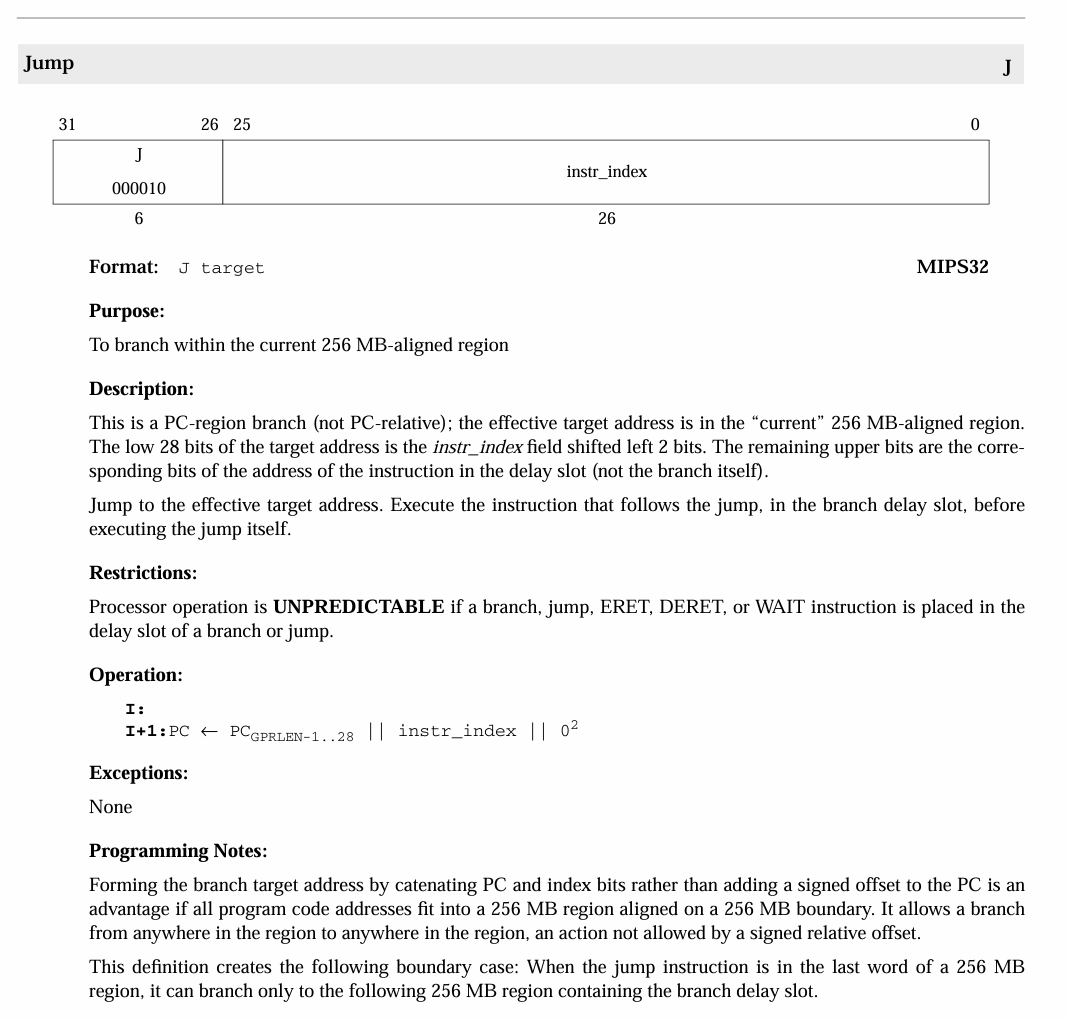
我们关注图中的这两句话:
The remaining upper bits are the corresponding bits of the address of the instruction in the delay slot (not the branch itself).
This definition creates the following boundary case: When the jump instruction is in the last word of a 256MB region, it can branch only to the following 256 MB region containing the branch delay slot.
( jal 指令的说明中也有这两句话,这里就不放图片了)
第一句话表明了,当开启延迟槽时,j 指令和 jal 指令的跳转地址计算中,PC 值的最高 4 位来自延迟槽中指令的 PC 值,而非 j 指令和 jal 指令本身的 PC 值。
第二句话指出了可能会出现的一个小问题,我们考虑这样一种情况:当 j 指令或 jal 指令的地址是 0x0ffffffc 时,延迟槽指令的地址就会是 0x10000000 ,两条指令的 PC 值最高 4 位并不相同。我们可能会以为跳转地址的范围应该是 0x00000000 到 0x0ffffffc ,但是实际上并非如此,跳转地址的最高 4 位应该从延迟槽指令中取得,也就是 0x10000000 到 0x1ffffffc !
在接下来要实现的五级流水线 CPU 中,我们需要开启延迟槽,当然这也会为我们的电路带来一些细小的改变。不过可千万不要认为延迟槽是为了增加实现难度而故意设置的挑战,其实恰恰相反,延迟槽是为了方便我们的设计(同时也是为了增加 CPU 效率)才提出的!随着我们深入了解五级流水线的设计,我相信你就能够理解为什么延迟槽是个好东西了!
5.2 五级流水线 CPU 的基本构造
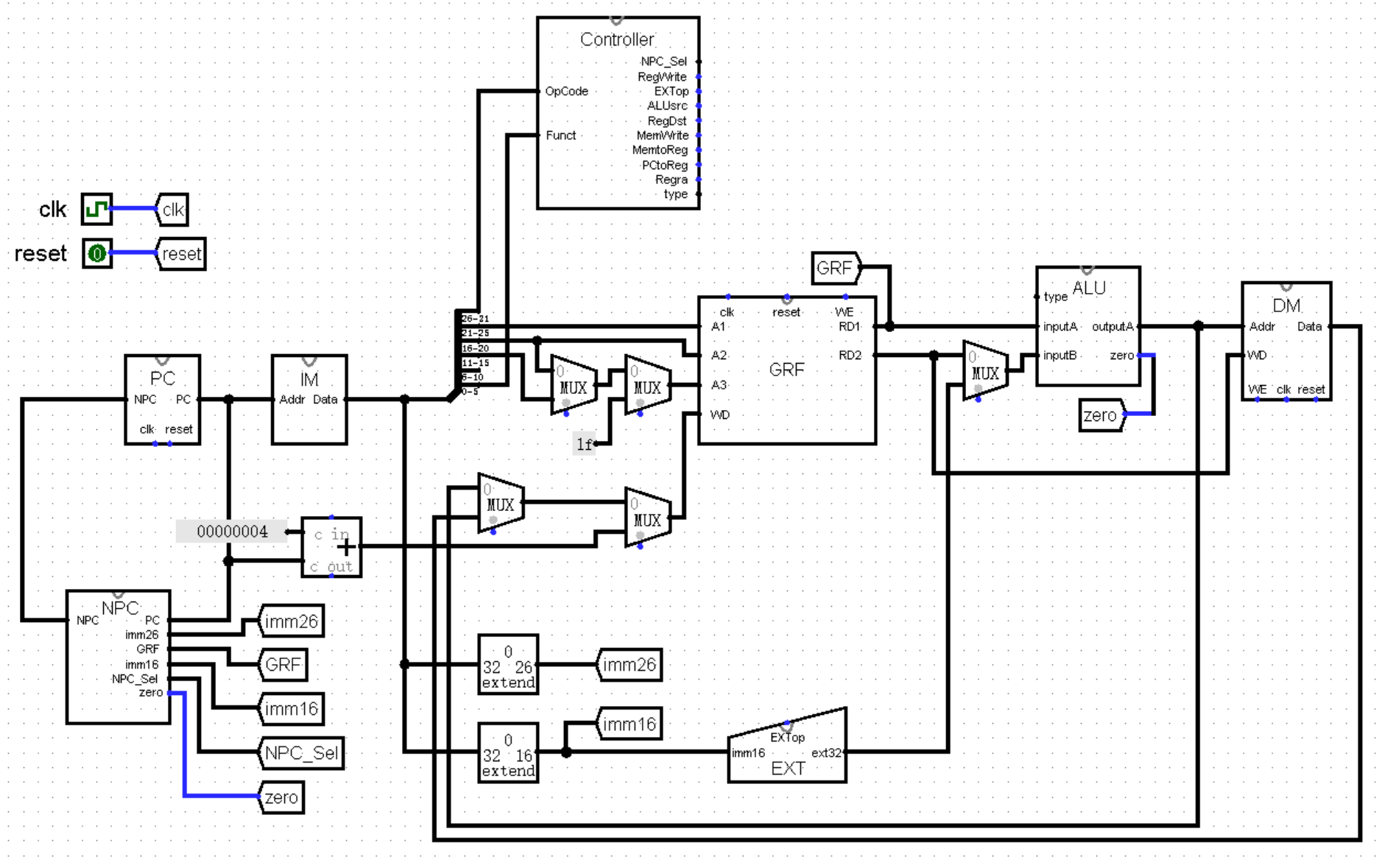
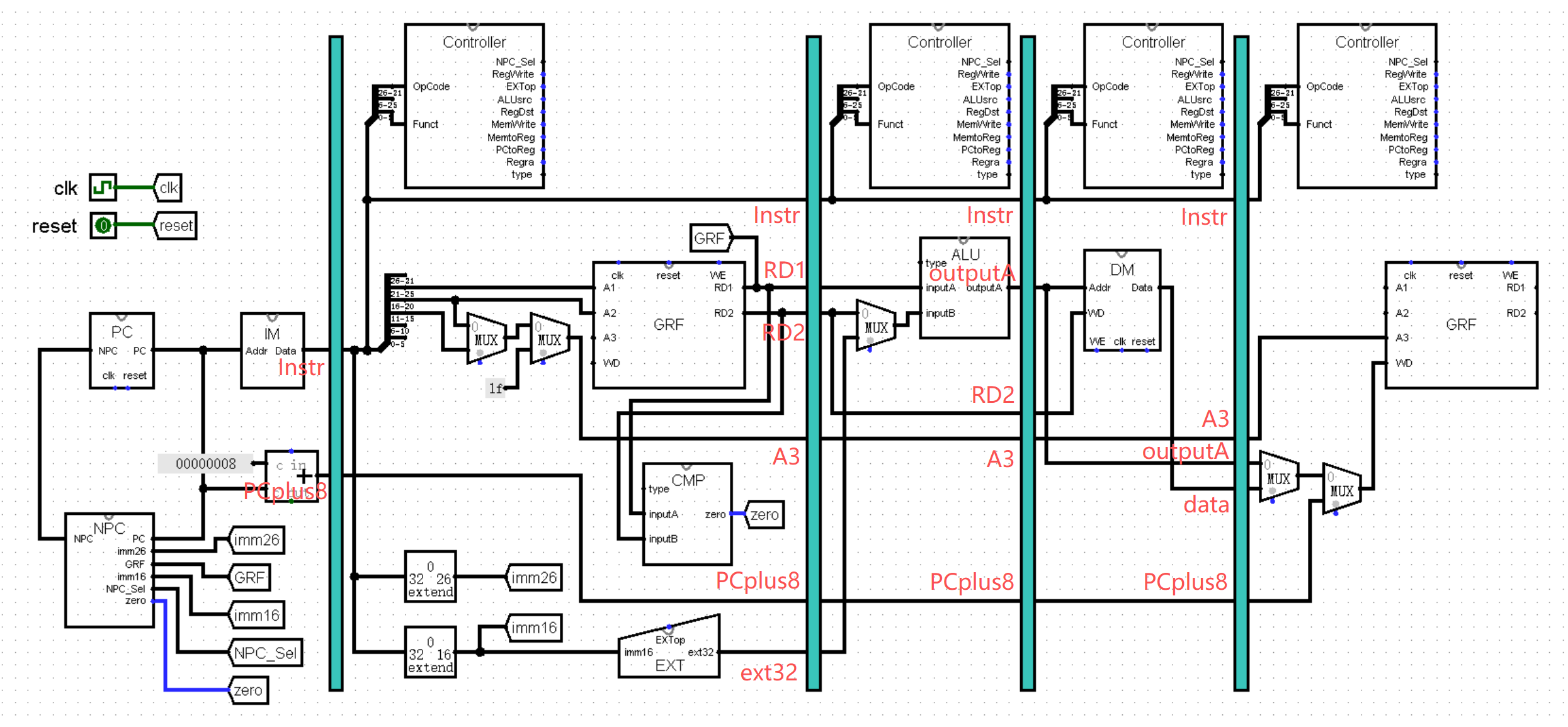
在这一节中,我们将通过 Logisim 中的简化电路来了解五级流水线 CPU 的基本构造。不过我们目前的单周期 CPU 就已经挤成一坨了,为了便于观看,接下来的图片将会省略部分不影响理解的 Controller 的选择接口,以及 clk 和 reset 接口。下面是省略了部分接口的单周期 CPU ,你能根据这幅图片理清指令的运行逻辑吗:
【五级流水线的划分】
在上一节我们了解到,我们需要将指令执行流程的各个步骤分离出来,形成 5 个不同的功能区,于是我们将电路图划分成这样:
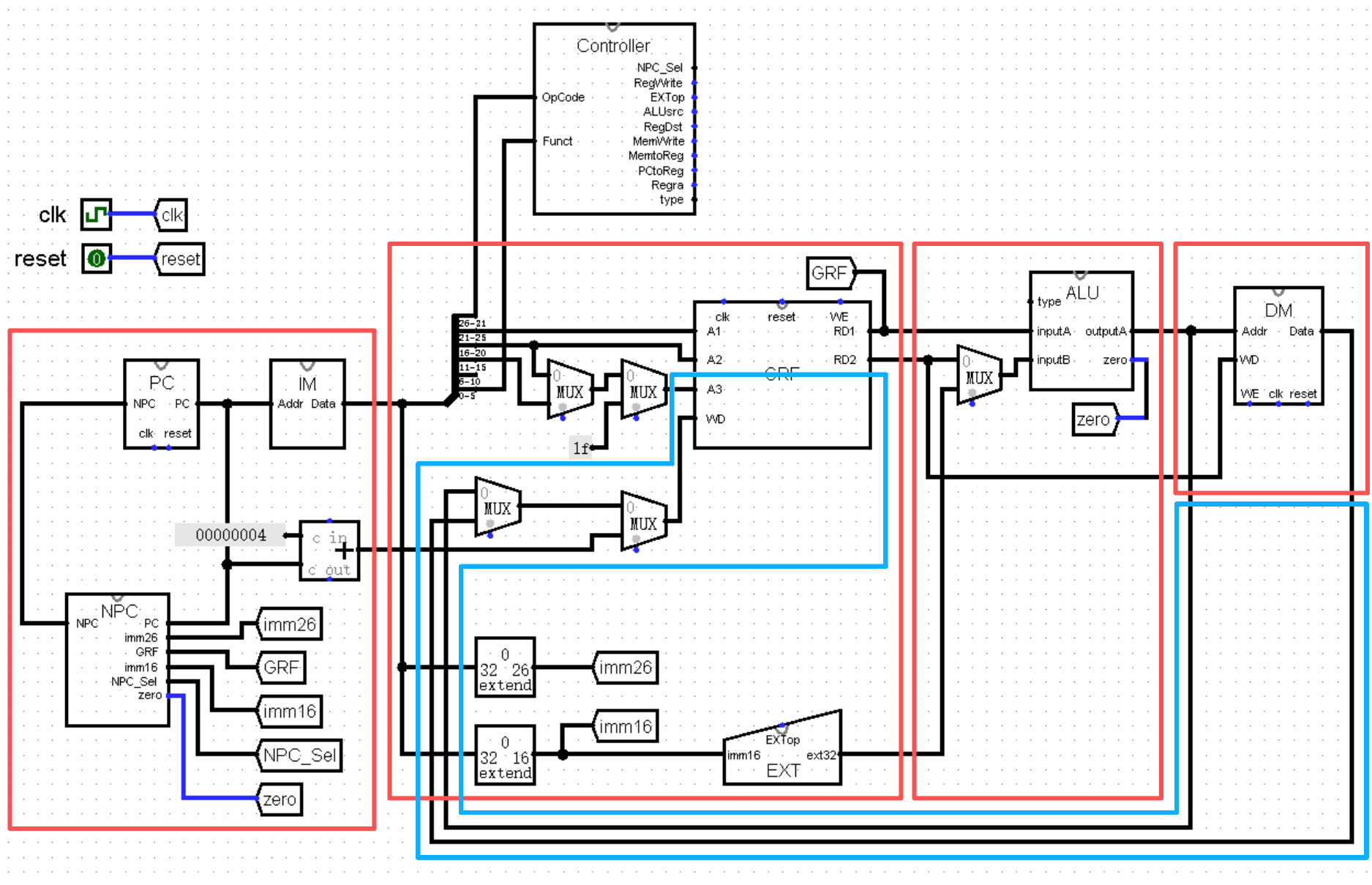
看似非常奇葩的划分方法,接下来我们来按顺序分析一下:
从左往右第一个红框是第一个功能区,我们称之为 F 级。F 级包括 PC 、NPC 、IM 三个模块,作用是根据当前的 PC 值取出对应的指令,当然也是每条指令执行的起点。
第二个红框(不包括蓝框中的部分)是第二个功能区,我们称之为 D 级。可以看到它被蓝框抠掉了一大部分,剩下了半个 GRF 模块和一个 EXT 模块。它的作用是根据 A1 A2 接口的寄存器编号,从 GRF 中取出相应的寄存器值 RD1 和 RD2 ;以及将 16 位立即数 imm16 拓展为 32 位,供下个功能区的 ALU 模块使用。
第三个红框和第四个红框分别是第三个功能区和第四个功能区,分别称之为 E 级和 M 级。两个功能区都只有一个模块,E 级的 ALU 模块负责计算,而 M 级的 DM 模块负责读写内存,非常简单朴素的两个功能区(但愿以后还是这样)。
最后就是奇形怪状的蓝框了,它就是第五个功能区,称为 W 级,负责将数据写回 GRF 模块中 A3 对应的寄存器。为了方便观看,我们在接下来的图片中将 W 级从 D 级中分离出来,放置在 M 级的下游:
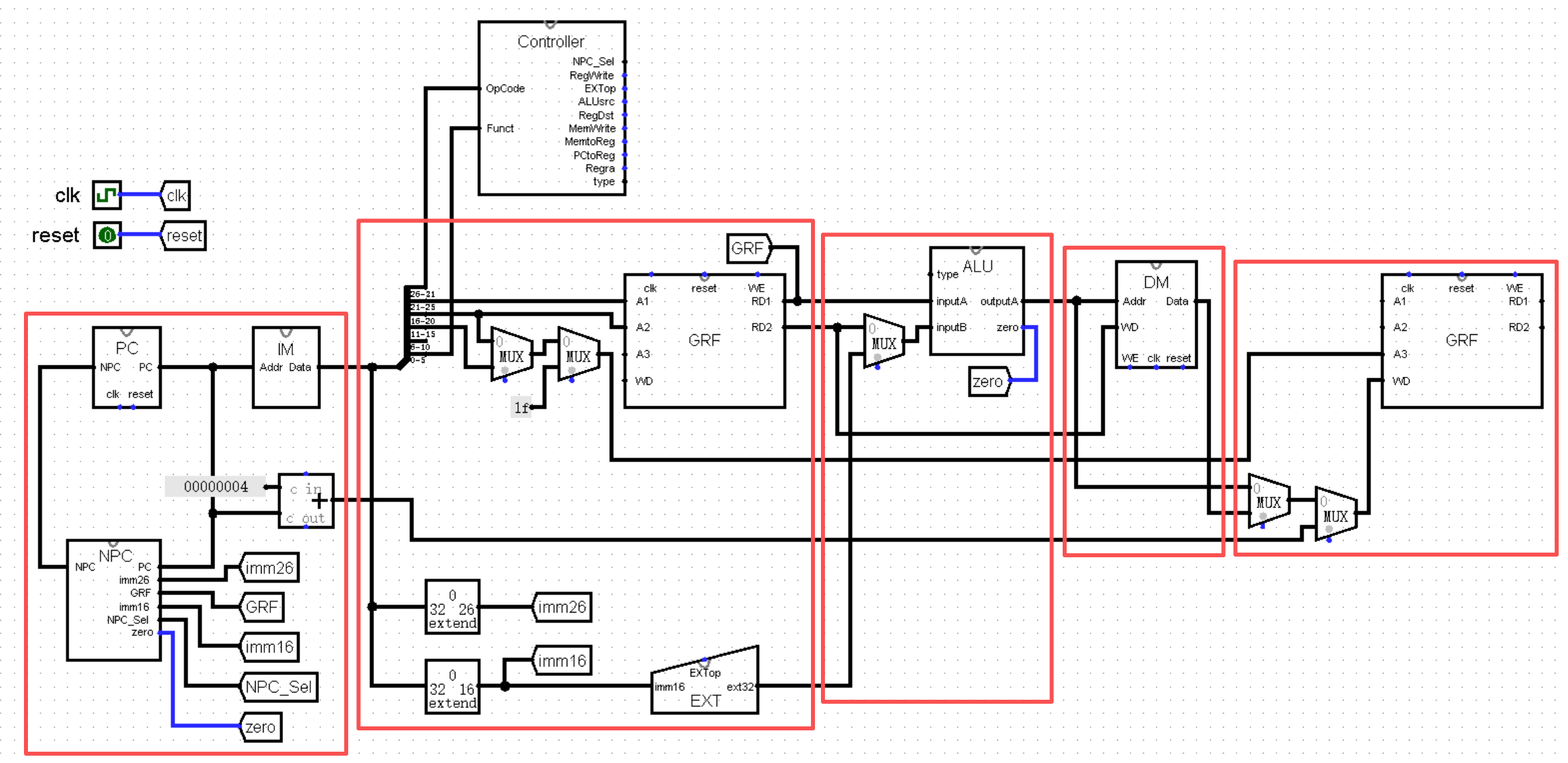
需要格外注意的是,图中的 GRF 模块看似分裂成了两块,实际上它们还是同一个模块,这里只是为了观看方便而进行的艺术化处理!!!
【流水线寄存器】
目前我们已经将我们的 CPU 分为了五个不同的功能区,然而当前的电路依然只能够满足一条指令在其中执行。为了让五个功能区能够分别执行自己的指令,我们需要在每两个功能区之间加上一个超大型寄存器,负责在每个时钟上升沿将上一级输出的所有内容原封不动流水到下一级,这样就能够实现每级一条指令的需求:
以防你没有理解流水线寄存器的内部结构,其实就是为每根接入的导线用寄存器延迟一下,像下图这样,非常简单:
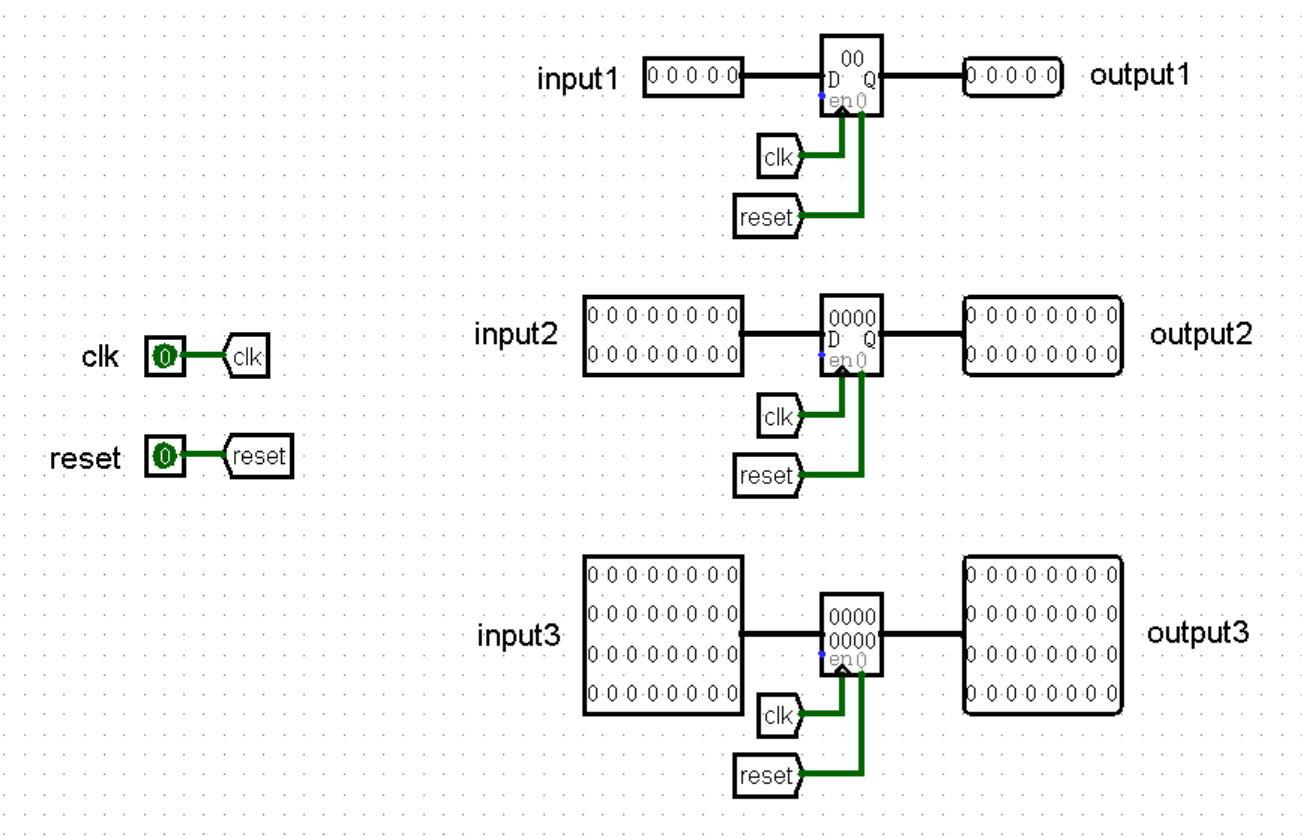
(这里输入端的个数和位宽都是随便画的,可以根据需要自由调整)
【适配延迟槽、CMP模块】
在本章中,我们为五级流水线 CPU 启用了延迟槽,所以当然也需要做一些适当的改造。
首先,我们需要调整一下 jal 指令和 jalr 指令存储地址的行为。根据 MIPS 指令的定义,在开启延迟槽的情况下,执行 jal 指令和 jalr 指令时不再会将 PC + 4 的值存入寄存器中,而是存入 PC + 8 ,也就是 jal 指令或 jalr 指令后第二条指令的地址。所以我们应该将随指令一起流水的地址值改为 PC + 8 :
接下来,我们来考虑一下跳转地址,也就是 NPC 模块输出值的计算问题。如果延迟槽没有开启,那么当跳转指令处在 F 级的时候,我们就需要计算出下一条要执行的指令的地址,也就是要向 NPC 模块提供所有输入接口( PC imm16 imm26 GRF NPC_Sel zero )的值,这样才能保证我们能够及时取出下一条要执行的指令。
当延迟槽开启时,我们就不需要这么着急了!当 F 级的指令是跳转指令时,由于延迟槽的存在,下一条要执行的指令的地址一定是当前的 PC 值加 4 ,所以我们可以等到跳转指令进入 D 级再来向 NPC 模块提供输入接口的值。
当跳转指令进入 D 级时,我们就需要着手向 NPC 模块提供信息了。从上面的图片中我们可以看出,imm16 imm26 和 GRF 接口的值,正是从 D 级传给 NPC 模块的。需要注意的是,这里所有的值由 D 级向前传递至 F 级的 NPC 模块,都不需要经过流水线寄存器(如上图所示),因为我们要实现的功能就是使 D 级的跳转指令能够实时修改 F 级中 NPC 模块的信息,如果经过流水线寄存器延迟,就没办法在下个时钟上升沿之前改变即将进入 F 级的指令的地址了!
同样的,我们还需要在跳转指令位于 D 级时,向 NPC 模块提供 PC NPC_Sel 和 zero 接口的值,不过这几位就有点不听话了,多少都整了点小活,我们挨个来看看怎么回事:
首先是 PC 接口的值,当 D 级的指令是跳转指令时,我们可以从 D 级传回当前跳转指令的 PC 值,用于计算即将跳转到的地址;但在每个周期 F 级也都会传入一个 F 级当前指令的 PC 值,用于计算非跳转情况下下一条指令的地址,也就是 PC + 4 。我们知道,如果 D 级是跳转指令,由于延迟槽的开启,F 级指令的 PC 值一定等于 D 级指令的 PC 值加 4 ,所以我们实际上并不一定需要向 NPC 模块传递 D 级指令的 PC 值,当 D 级指令为跳转指令时,我们只需要将当前 F 级指令传递的 PC 值减去 4 ,即可得到 D 级相对跳转指令的 PC 值了!
(这一段非常拗口,不过还是一定要把其中的逻辑消化到位,务必要分清 F 级 PC 值和 D 级 PC 值的区别,搞清楚每种 NPC 计算方式中,用到的 PC 值是两种中的哪一种!)
下面是 NPC 计算的完整逻辑,可以假设 F 级是任意指令(当然如果 D 级是跳转指令的话,F 级就只能是非跳转指令了),D 级分别是非跳转指令、相对跳转指令、绝对跳转指令等各种情况,根据预期跳转的结果,思考一下 NPC 的计算值为什么是这样的:
1 | if D 级为非跳转指令 or D 级为相对跳转指令,但不满足跳转条件 then |
接下来是 NPC_Sel 接口的值,这个值需要通过 Controller 模块产生,在后续讲解 Controller 模块时我们再作研究,现在暂且先放过它。我们目前只需要记住 NPC_Sel 接口的值是在 D 级产生的,而不是 F 级就可以了。
最后是 zero 接口的值,这也是一个比较麻烦的问题,因为从上面的图片中我们可以发现,zero 的值是在 E 级的 ALU 模块中产生的。延迟槽的存在让我们可以把 NPC 的计算拖到 D 级,而 zero 竟然想再拖到 E 级,这是万万不可以的,所以我们一定要想个办法,将 zero 的计算提前到 D 级。
这是能够做到的吗?我们思考一下,发现这当然是可以做到的!事实上,在相对跳转指令的跳转条件判断中,我们一般都是使用两个寄存器的值进行比较,而这两个值在 D 级中就已经能够取到了,我们只不过是把 比较 这个过程放在了 E 级的 ALU 模块而已。所以实际上我们只需要将 比较 这个过程从 E 级的 ALU 模块中抽离出来放在 D 级,就完全可以在 D 级就得到 zero 的值了!
于是我们仿照 ALU 模块,在 D 级建立一个相似的模块 CMP ,将 ALU 模块中 zero 的逻辑移至 CMP 模块中。从此,ALU 模块的 zero 接口正式告别了历史舞台:
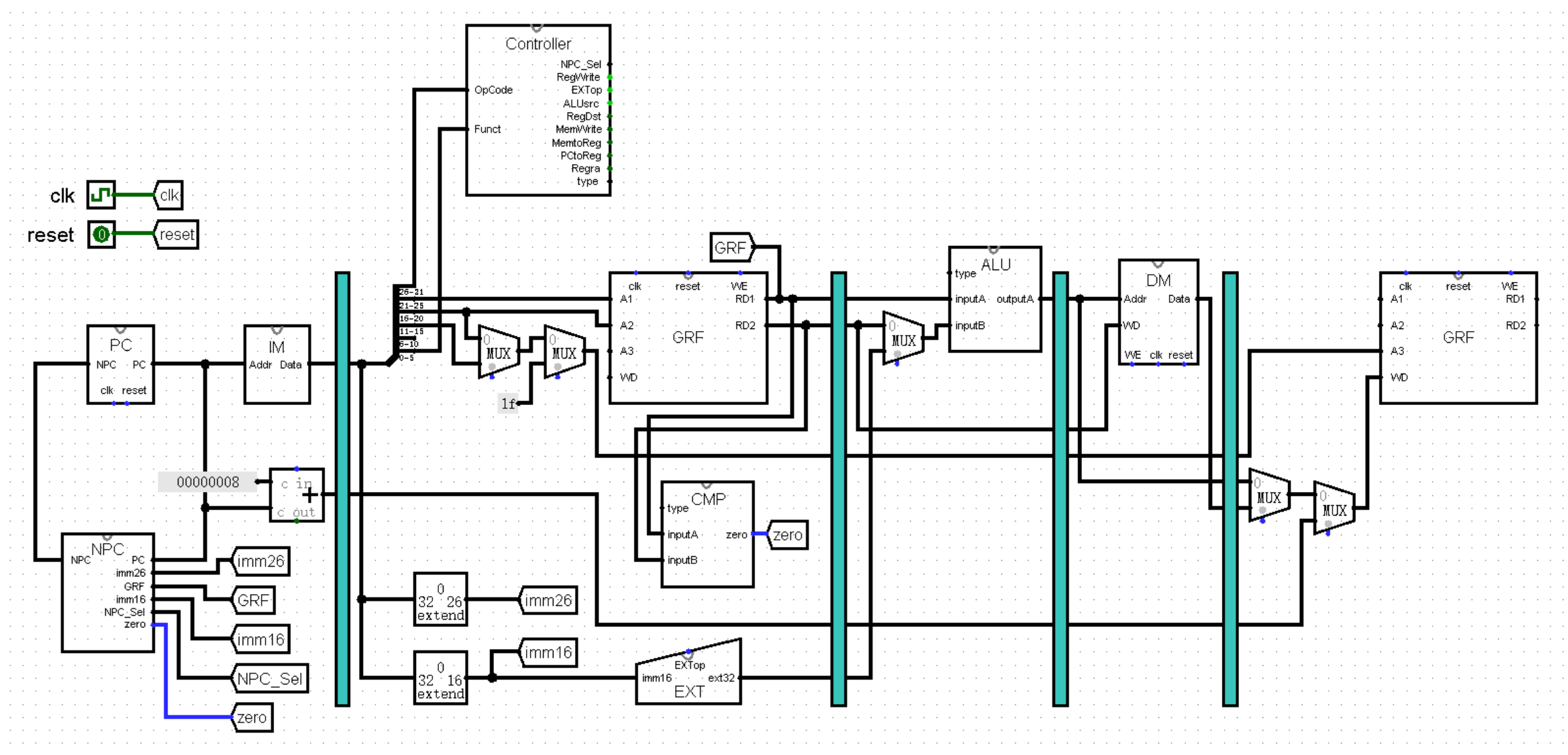
【Controller模块的改造】
终于,我们要来解决一个你肯定已经发现了很久的问题,那就是刚才我们分级的时候,好像把 Controller 模块给落下了!那么 Controller 模块究竟属于哪一级呢?
我们知道,Controller 模块是区分不同指令的核心,控制着 CPU 中的每一个选择信号,这些信号分散在 CPU 的各级中,在 D 级、E 级、M 级、W 级都会用到( F 级的 NPC_Sel 接口已调任至 D 级,望周知)。
面对这种情况,我们能够很自然地想到一种方法,那就是将 Controller 放在 D 级,在 D 级产生所有选择信号,接下来让这些信号随指令一起流水,像下图这样:
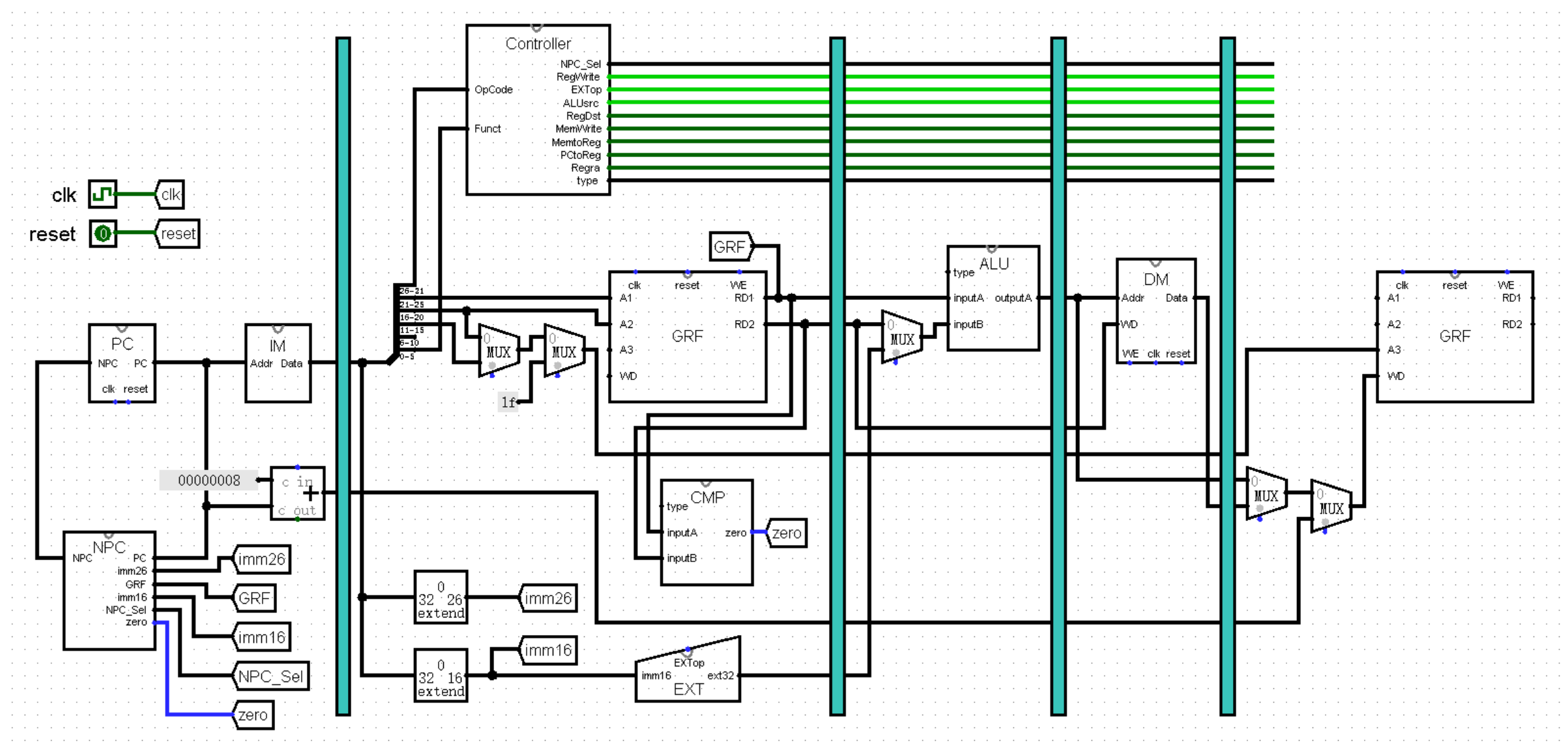
这种做法其实是一种非常主流的做法,这样实现完全没有任何问题。不过我个人觉得流水每个选择信号写起来还是太麻烦了,所以我选择另外一种做法,那就是为每级都设置一个 Controller :
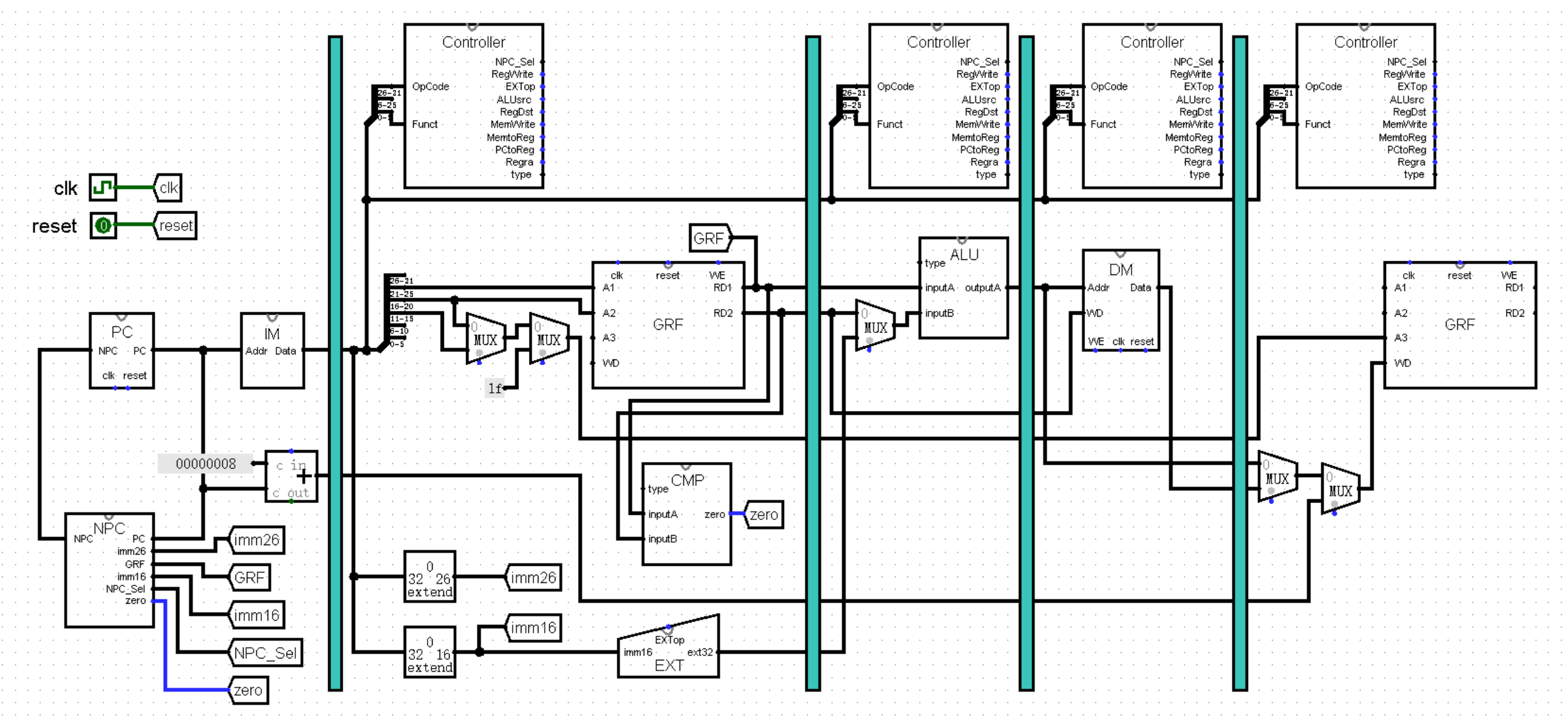
(因为我喜欢这种做法,所以之后的内容中都会以这种架构进行演示)
那么到目前为止,我们就已经完成了所有最基础的五级流水线改造。是的,我们的工作还远远没有结束,甚至可以说是才刚刚开始!接下来的部分才是五级流水线 CPU 的精髓,令往届同学放弃爱情,为之彻底疯狂的 ——
5.3 阻塞与转发
【阻塞的概念】
不知道你是否已经发现了,当前我们的 CPU 还存在着一个极其严重的结构性问题,严重到只用两条 MIPS 指令就会出现 bug ,我们来看下面这个例子:
1 | addiu $t1, $t0, 1 |
这两条指令正确执行结果应该是 $t1 寄存器被赋值为 1 ,$t2 寄存器被赋值为 2 。可是我们将其输入到我们的 CPU 中,却发现 $t1 和 $t2 两个寄存器的值都是 1 !这是为什么呢?
我们来将两条指令放在五级流水线中观察。当前一条指令处于 D 级时,这条指令能够正确取出 $t0 寄存器的值(为默认值 0 )。但在下一个周期,前一条指令处于 E 级,正在计算 $t1 寄存器的值时,后一条指令就已经到达 D 级,此时前一条指令还没有将计算的结果写回 $t1 寄存器中,于是后一条指令取到的 $t1 寄存器的值仍然是默认值 0 ,这就导致了 $t2 寄存器的值出现计算错误!
当然,这个问题也有一个非常简单粗暴的解决办法。既然问题在于后一条指令读寄存器时,前一条指令还没有来得及写入寄存器的值,那么我们只需要让后一条指令稍作等待,等前一条指令离开 W 级之后,再让后一条指令进入 D 级读取就可以了。这种让后面的指令等待前面的指令提供寄存器值的解决方法,就被称之为“阻塞”。
当然,如果前一条指令继续流水,后一条指令原地不动,那两条指令之间就会出现空档,此时我们可以直接清空两条指令中间的数据,其实也就相当于在两条指令中间插入了空泡指令 nop :
| 周期 | F级 | D级 | E级 | M级 | W级 |
|---|---|---|---|---|---|
| T0 | addiu | addiu | |||
| T1 | addiu | nop | addiu | ||
| T2 | addiu | nop | nop | addiu | |
| T3 | addiu | nop | nop | nop | addiu |
| T4 | addiu | nop | nop | nop |
(这下知道 nop 指令有什么用了吧)
【转发的概念】
然而,如果我们只使用阻塞,每当遇到类似的情况,CPU 都会停摆 3 个周期。实际上,当我们的 CPU 运行真正的汇编程序时,这种连续多条指令使用同一个寄存器的情况是非常常见的,所以只使用阻塞来解决问题还是有点太浪费时间了。那么有没有一种能够让 CPU 不停摆的解决方法呢?答案就是“转发”!
我们还是以之前的两条指令为例,仔细思考一下整个执行过程。前一条指令真的需要到 W 级才能得到将要写入 $t1 寄存器的值吗?实际上并非如此,这个要写入的值实际上在 E 级就已经完成计算,只不过尚未存入 GRF 模块中而已。后一条指令真的需要在 D 级就拿到 $t1 寄存器的值吗?其实也并不需要,只要在 E 级进入 ALU 模块之前拿到 $t1 寄存器的值,就完全来得及正常进行计算。
于是,我们可以建立一条“紧急传送通道”,让前一条指令刚进入 M 级,后一条指令刚进入 E 级时,前一条指令就将计算出来的 outputA 值直接传给后一条指令,作为 inputA 值再次输入 ALU 模块,刚好卡出了一个完美的 timing ,在 CPU 不停摆的情况下解决了问题,这种解决方法就是“转发”:
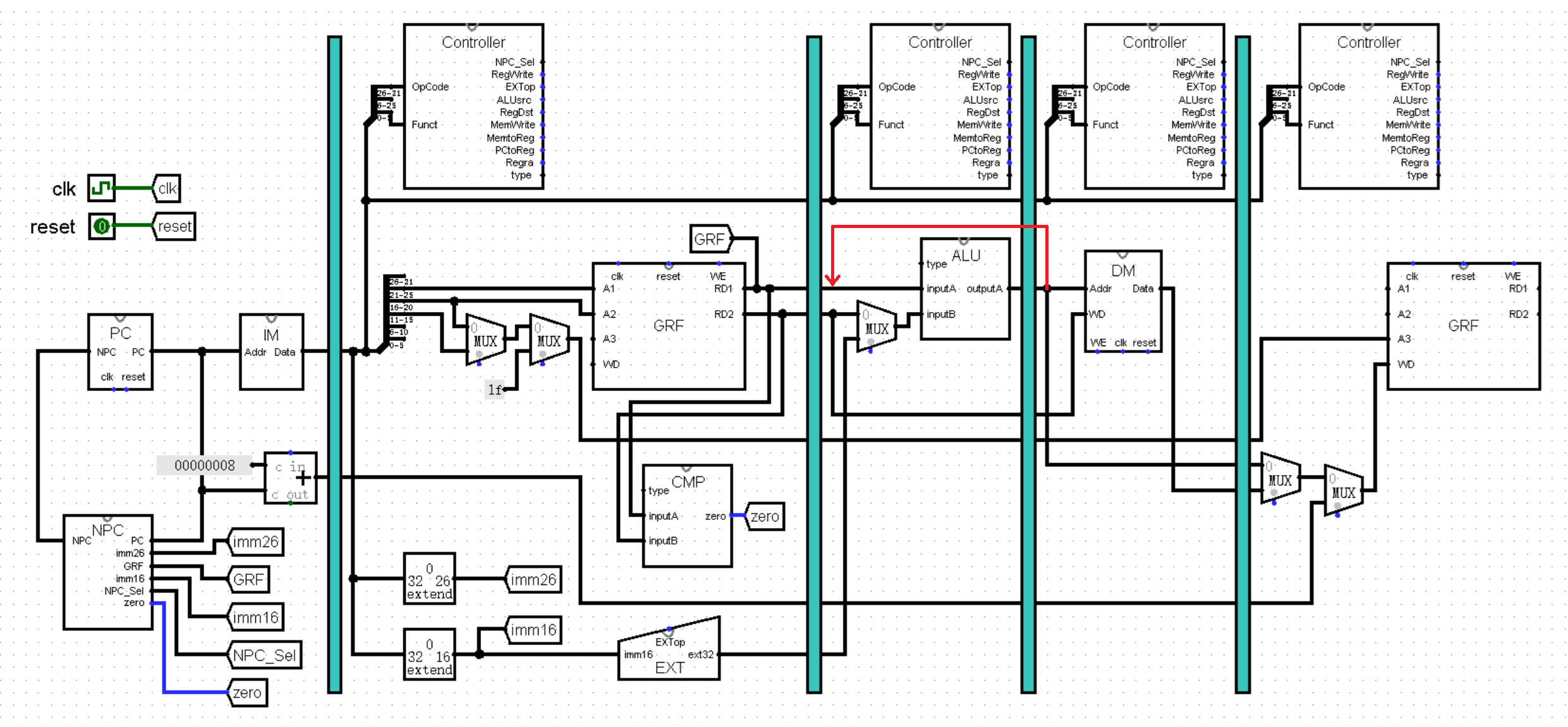
这里要说明几个细节。首先就是转发的过程肯定是不需要经过流水线寄存器的,我们设计转发的目的就是构建一个最高效的数据通路,当然不会在这种地方浪费一个周期。
另外就是一个经典问题,为什么我们不能在 E 级 ALU 模块计算出数据后就直接转发,而是要等到 M 级才进行转发?我们可以这样理解,在真实的 CPU 中,为了提高 CPU 的运行效率,一个时钟周期的时间大约就等于运行时间最长的一级的运行时间,而数据在模块中的运行时间,几乎占据了该级运行时间的全部,数据在主模块中导线和 MUX 的时间几乎可以忽略不计。所以如果在模块的后面开始转发,就有可能会出现在一个周期中间甚至是末尾的时候数据发生改变的情况,此时转发终点处的数据可能来不及计算完(例如图中的转发终点,新数据还需要再经过一次 ALU 模块进行计算),下个时钟上升沿就已经到来,导致没能够赶上流水,数据出现错误;而只要保证转发起点在任何模块之前,就可以认为是在一个周期的刚开始就进行了转发,于是就不会出现上面那种来不及的情况了。
(实际上这种问题只存在于时钟周期巨短无比的情况下,我们的 CPU 因为时钟周期足够长,根本不可能发生这种情况,不过我们还是要假装自己在设计真正的 CPU ,遵守一下设计规范~)
当然了,我们的 CPU 在实际执行各种指令时,会出现的问题要比刚才的例子复杂得多。理论上来说,距离在三条指令之内,前面的指令要写的寄存器和后面的指令要读的寄存器相同时,都有可能会出现寄存器的冲突问题。最严重的情况下,可能会出现连续四条指令两两之间全部冲突。但是,只要我们使用转发的思想,就能够解决绝大多数的问题!
什么是转发的思想?对于两条可能会发生冲突的指令,我们不再去考虑前一条指令什么时候需要写寄存器,后一条指令什么时候需要读寄存器,而是去考虑前一条指令什么时候产生要写入寄存器的值,以及后一条指令什么时候需要用到寄存器的值。只要这两个时间节点满足一定条件,那么两条指令之间的冲突就是可以用转发来解决的!
【转发的触发条件】
(观前警告:本书中关于转发和阻塞的计算方法,与指导书中的计算方法并不相同,请注意辨别,千万不要学串了!)
接下来我们就来研究一下,当前后两条指令满足什么条件,我们就可以使用转发来解决两者之间的冲突呢?
首先当然需要满足一些基本条件。比如:前一条指令有要写的寄存器;后一条指令有要读的寄存器(如果有两个要读寄存器,分别计算即可);前一条指令要写的寄存器和后一条指令要读的寄存器相同;这个相同的寄存器不能是 0 号寄存器。这些前提条件看似极其显然,但在设计电路时万万不可或缺,否则就会出现胡乱转发的现象!(尤其是 0 号寄存器那条,让我回忆起新主楼通宵 debug 的夜晚,悲)
接下来就是一些奇妙的小计算。我们从直观上来想,如果前一条指令要写入寄存器的值产生得比较早,后一条指令要用到寄存器的值的时间比较晚,那么我们就能够及时地进行转发,卡上这个 timing ;如果前一条指令要写入寄存器的值产生得非常晚,后一条指令要用到寄存器的值的时间又很早,那就有可能赶不上转发,这时候就需要另想别的办法了。
在接下来的计算中,我们令 D 级、E 级、M 级、W 级分别为 0 、1 、2 、3 。
设前一条指令产生要写入寄存器的值的流水线级为 $t$(注意这里指的是可以进行转发的级别),例如 addiu 指令在 M 级可以进行转发,于是 addiu 指令的 $t$ 值为 2 ;
设后一条指令要用到 rs 寄存器的值的流水线级为 $t_{rs}$ ,要用到 rt 寄存器的值的流水线级为 $t_{rt}$ ,例如 addiu 指令在 E 级会用到 rs 寄存器的值,所以 $t_{rs}$ 的值为 1 ,addiu 指令不会用到 rt 寄存器的值(这里指不会读取 rt 寄存器),所以 $t_{rt}$ 的值不存在,不需要参与计算;
设两条指令所在级别的差为 $\Delta t$ ,例如两条相邻指令的 $\Delta t$ 值为 1 。
根据这些值,你能否给出满足转发条件的不等式呢?答案如下:
$$ t_{rs} \geq t - \Delta t,~~~ t_{rt} \geq t - \Delta t $$
其实推导过程也非常简单,看你能不能转过这个弯:对于前一条指令,当它刚好能够产生要写入的寄存器的值时,它所在的流水线级为 $t$ ,此时后一条指令所在的流水线级应该是 $t - \Delta t$ 。当这个流水线级小于等于 $t_{rs}$ 时,就来得及向 rs 寄存器的值进行转发;当这个流水线级小于等于 $t_{rt}$ 时,就来得及向 rt 寄存器的值进行转发。这好像是个洛伦兹变换
然而,在我们的 CPU 实际运行时,处于 D 级到 W 级的四条指令,两两之间都需要计算 $\Delta t$ ,写起来会十分复杂,于是我们将两指令之间的距离 $\Delta t$ 转换为 前一条指令到 D 级的距离 与 后一条指令到 D 级的距离 的差,即 $\Delta t = t_1 - t_2$ ,于是我们将不等式改为以下形式:
$$ t_{rs} - t_2 \geq t - t_1,~~~ t_{rt} - t_2 \geq t - t_1 $$
最后,我们设 $t_{rs} - t_2$ 为 $t_{rsuse}$ ,$t_{rt} - t_2$ 为 $t_{rtuse}$ ,$t - t_1$ 为 $t_{new}$ ,即可得到我们最终的计算公式:
$$ t_{rsuse} \geq t_{new},~~~ t_{rtuse} \geq t_{new} $$
非常简洁,有一种大道至简的美感~
接下来我们来分析一下具体的计算流程。我们的计算过程中最关键的指标是 $t_{rs}$ 、$t_{rt}$ 和 $t$ ,它们都是定值,不随指令的流水发生任何改变。
对于需要进入 CMP 模块进行比较的相对跳转指令,它们在 D 级就需要用到 rs 和 rt 寄存器的值,于是它们的 $t_{rs}$ 和 $t_{rt}$ 值均等于 0 ;对于 jr 和 jalr 这些需要用到 rs 寄存器的值作为跳转地址的指令,它们需要在 D 级向 NPC 模块提供 rs 寄存器的值,于是它们的 $t_{rs}$ 值也为 0 ;对于需要在 E 级进入 ALU 模块计算的指令,参与计算的寄存器的 $t_{rs}$ 或 $t_{rt}$ 值为 1 ;对于 sw 等写内存指令,它们的 rt 寄存器值不参与 ALU 模块的运算,在 M 级存入 DM 模块时才会使用到,于是这些指令的 $t_{rt}$ 值为 2 。
在写寄存器的指令中,写入值由 ALU 模块计算产生的指令,在 M 级能够进行转发,于是它们的 $t$ 值为 2 ;写入值从 DM 模块中读取产生的指令,在 W 级能够进行转发,于是它们的 $t$ 值为 3 ;特殊地,jal 和 jalr 指令的写入值 PC + 8 从一开始就已经产生,于是它们的 $t$ 值为 0 。
下面是记录了目前所有指令 $t_{rs}$ 、$t_{rt}$ 和 $t$ 值的表格,你也可以尝试着先自己完成这幅表格,再与答案对照,加深自己的理解:
| 指令 | addu | subu | addiu | xori | lui | lw | sw | beq | bne | j | jal | jr | jalr |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| $t_{rs}$ | 1 | 1 | 1 | 1 | X | 1 | 1 | 0 | 0 | X | X | 0 | 0 |
| $t_{rt}$ | 1 | 1 | X | X | X | X | 2 | 0 | 0 | X | X | X | X |
| $t$ | 2 | 2 | 2 | 2 | 2 | 3 | X | X | X | X | 0 | X | 0 |
( X 表示相应的值不存在)
接下来,我们在计算 $t_{rsuse}$ 、$t_{rtuse}$ 和 $t_{new}$ 值时,只需要将 $t_{rs}$ 、$t_{rt}$ 和 $t$ 值减去指令对应的流水线级即可。为了防止 $t_{rs}$ 、$t_{rt}$ 、$t$ 值出现负数可能带来的莫名其妙的情况,我们规定若计算出的 $t_{rs}$ 、$t_{rt}$ 、$t$ 值小于 0 ,则直接记为 0 。这里我们不对这条规则的正确性作严格推导,因为它的推导需要用到后续阻塞部分的知识,我们目前只需要记住这条规则即可。
举个例子,对于 addiu 指令,它在 D 级的 $t_{rsuse}$ 值为 1 ,$t_{new}$ 值为 2 ;在 E 级的 $t_{rsuse}$ 值为 0 ,$t_{new}$ 值为 1 ;在 M 级的 $t_{rsuse}$ 值为 0 ,$t_{new}$ 值为 0 ;在 W 级的 $t_{rsuse}$ 值为 0 ,$t_{new}$ 值为 0 。整体呈现单调递减的趋势。
本部分的最后一个问题,对于两条处于 D 级到 W 级的指令,只要它们满足寄存器相同等基础条件,以及 $t_{rsuse} \geq t_{new}$ 或 $t_{rtuse} \geq t_{new}$ 的条件,就一定会发生转发吗?
理论上来说,只有当前面的指令的 $t_{new}$ 值等于 0 时,我们才需要进行转发;当前面的指令的 $t_{new}$ 值大于 0 时,这条指令还没有产生要写入的值,无法提供正确的转发值。
不过,在实际编写过程中,我们往往忽略该条件,无论前面的指令的 $t_{new}$ 是否为 0 都进行转发。这是因为,虽然此时的转发值大概率是个错误的值,但我们能保证这个错误的值不会被使用,且最终前面的指令一定能向后面的指令转发正确的值!
这是因为 前面的指令的 $t_{new}$ 值 和 后面的指令的 $t_{rsuse}$ 值(或 $t_{rtuse}$ 值,接下来统称为 $t_{use}$ 值)都在以每周期减 1 的速度减小。因为 $t_{use} \geq t_{new}$ ,所以当 $t_{new}$ 减小为 0 之前,$t_{use}$ 一定大于 0 ,于是就保证了错误的转发值不会被使用;另外,当 $t_{new}$ 减小到 0 时,$t_{use} \geq t_{new}$ 依然成立,所以能够保证最终一定能够进行正确的转发。
【转发的数据通路】
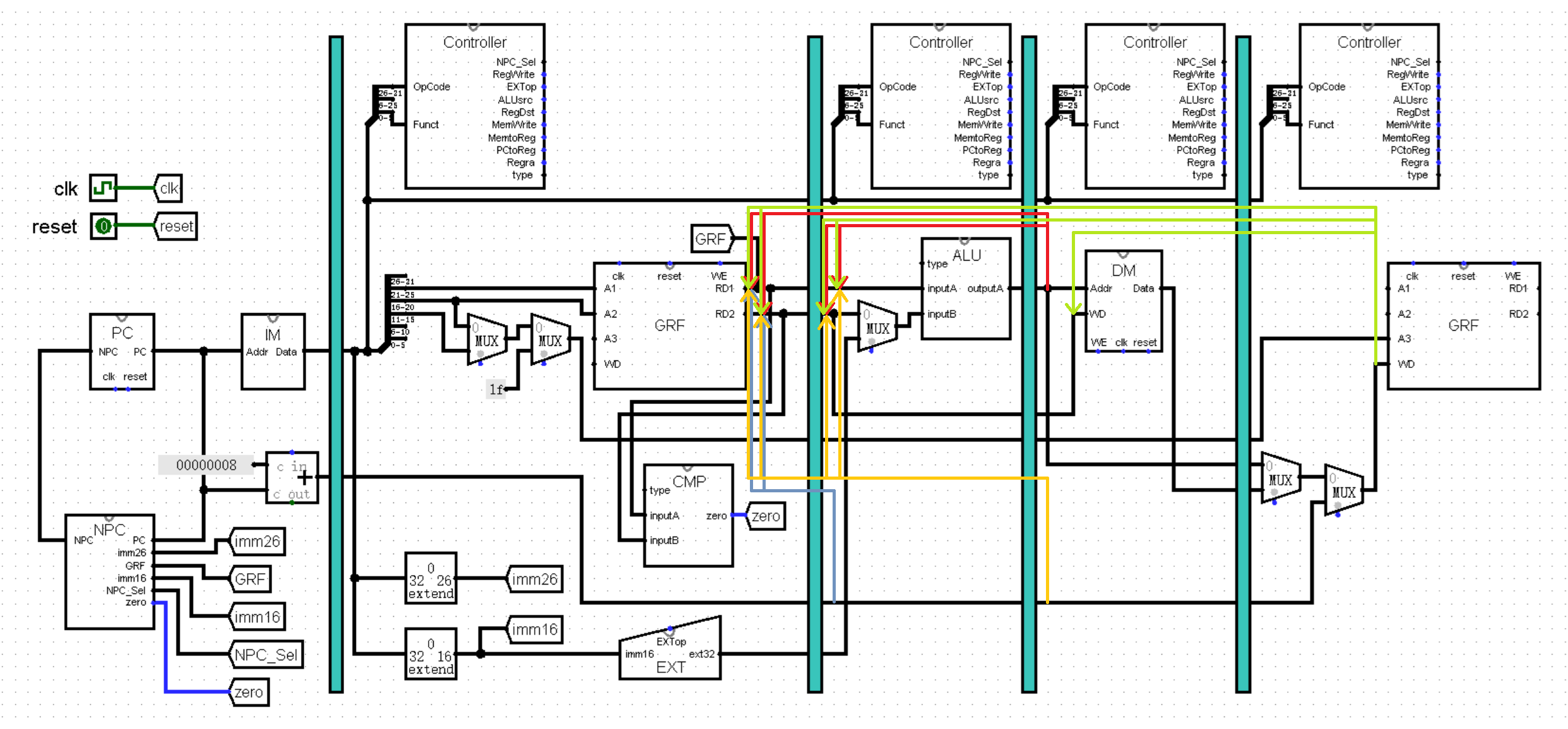
接下来,我们再来分析一下转发的数据通路,也就是来探究一下所有转发情况的起点和终点:
(提前公布一下答案,转发一共有 15 种不同的数据通路,你能将它们全部找到吗?)
首先我们来分析一下转发数据通路的终点。已经掌握了转发思路的你一定能够想到,终点所在的位置必然是需要使用到 rs 或 rt 寄存器的值的模块之前。这样的模块有哪些呢?CMP 模块和 ALU 模块的 inputA 和 inputB 接口可能会用到 rs 和 rt 寄存器的值;当指令向内存中写入数据时,DM 模块的 WD 接口也需要用到 rt 寄存器的值,所以转发数据通路共有 5 种终点。
接下来是转发数据通路的起点。我们需要在每一级的开端,为每一条可能含有写入寄存器的值的导线创建转发数据通路。在之前我们找到了 ALU 模块的 outputA 端口,它的值可以在 M 级作为转发的起点。除此之外还有 GRF 的 WD 端口,即将写入 GRF 的值也可以在 W 级作为转发的起点。
我们已经找到了所有的数据通路了……吗?如果你认为你已经找全了,那你就要失去爱情了!说起为寄存器赋值,我们第一时间想到的就是 GRF -> ALU -> (DM) -> GRF 这条经典的数据通路,不过实际上还有另一条隐藏路线,作为全图中最长的一根导线大隐隐于市,它就是 PC + 8 !这条线路不经过我们刚才分析的任何一个转发数据通路的起点,从 F 级出发直达 W 级,在 jal 指令中为 $ra 寄存器赋值,在 jalr 指令中为 rd 寄存器赋值,所以我们还需要在每一级为这条不起眼的导线加上转发的数据通路!
实际上 PC + 8 的值在 D 级就已经可以转发,不过也没有指令需要在 F 级就用到寄存器的值,所以我们在 D 级可以不设转发通路的起点,不过在 E 级和 M 级都需要设置。事实上,我们在 W 级也可以不需要设置起点,因为此时 PC + 8 的值已经与经典数据通路的值汇合到了一起,不需要单独进行转发了。
综上所述,我们一共找到了 4 个转发数据通路的起点,5 个转发数据通路的终点,除去起点和终点在同一级,或者起点在终点后面的流水线级等不可能出现的情况,一共有下面 15 种转发数据通路:
需要注意的是,我们的 CPU 有可能会出现两条指令同时向同一个寄存器转发的情况,例如下面三条指令:
1 | lw $t1, 0($t0) |
当 lw 指令处于 W 级,addiu 指令处于 M 级,ori 指令处于 E 级时,lw 指令和 addiu 指令会同时向 ori 指令转发 $t1 寄存器的数据。此时,我们需要保证 ori 指令接收到的数据一定要是最新的,也就是 addiu 指令提供的数据。当一个转发数据通路的终点对应多个起点时,我们一定要注意它们之间的优先级关系!
【阻塞的触发条件】
在解决寄存器冲突问题时,我们研究了 $t_{rsuse} \geq t_{new}$ 和 $t_{rtuse} \geq t_{new}$ 的情况,此时可以转发进行处理;但当任何两级之间出现 $t_{rsuse} < t_{new}$ 或 $t_{rtuse} < t_{new}$ 的情况时,我们就无法通过及时转发来保证 CPU 完全不停摆了。为了保证指令执行的绝对正确性,我们只能稍微作出一些牺牲,暂时对我们的 CPU 进行阻塞。
在熟悉了转发条件的计算之后,我们能够非常简单地证明:在某个时刻,若两条指令满足 $t_{use} \geq t_{new}$ 的关系,那么在之后的任何时刻,这两条指令都一定满足 $t_{use} \geq t_{new}$ 的关系。
那么根据这个结论,我们就可以用反证法证明:在某个时刻,若两条指令满足 $t_{use} < t_{new}$ 的关系,则它们从一开始就应该满足 $t_{use} < t_{new}$ 的关系。
能理解其中的数学逻辑吗?没有理解也不要紧,其实我们只需要知道一个事实,那就是:我们只需要在后一条指令位于 D 级时,判断其是否需要阻塞即可!
于是,我们将 D 级指令的 $t_{rsuse}$ 和 $t_{rtuse}$ 分别与 E 级、M 级、W 级指令的 $t_{new}$ 进行比较,若 6 个比较中的任何一个满足 $t_{use} < t_{new}$ ,则需要对 D 级进行一个周期的阻塞。例如下面的两条指令:
1 | lw $t1, 0($t0) |
当 lw 指令运行至 E 级,addiu 指令运行至 D 级时,lw 指令的 $t_{new}$ 值为 2 ,而 addiu 指令的 $t_{rsuse}$ 值为 1 ,于是 $t_{rsuse} < t_{new}$ ,触发阻塞,lw 指令继续流水进入 M 级,而 addiu 指令停止在 D 级不动,在 E 级插入空泡指令 nop 。
在下一个周期,lw 指令运行至 M 级,addiu 指令依然位于 D 级,此时 lw 指令的 $t_{new}$ 值为 1 ,addiu 指令的 $t_{rsuse}$ 值为 1 ,于是 $t_{rsuse} \geq t_{new}$ ,即可进行转发。
同样是阻塞的方法,这种与转发衔接的阻塞不需要 CPU 停摆 3 个周期才能继续运行,只要阻塞到满足转发条件,直接进行转发即可。刚才的例子中只需要阻塞一个周期,当然也有需要连续阻塞两个周期的情况:
1 | lw $t1, 0($t0) |
当 lw 指令运行至 E 级,beq 指令运行至 D 级时,lw 指令的 $t_{new}$ 值为 2 ,而 beq 指令的 $t_{rsuse}$ 值为 0 ,所以需要连续阻塞两个周期,等到 lw 指令进入 W 级,$t_{new}$ 值为 0 时才可以进行转发。
【阻塞的实现细节】
接下来我们来分析一下这种阻塞的具体实现方法。当我们判断出需要将 D 级指令阻塞时,该如何操作各个模块和寄存器,使得能够实现阻塞的效果呢?
首先,我们需要确保阻塞期间的 PC 值不变。为了达到 CPU 停摆的效果,我们应当在下一个始终上升沿禁止 NPC 值写入 PC 模块,使 PC 值不会发生改变。所以我们需要为 PC 模块加入写使能接口 en ,当出现阻塞信号关闭 PC 模块的写使能。
另外,我们其实还需要保证在阻塞期间,NPC 值能够被正常计算。不过因为在阻塞期间,D 级的所有数据以及 F 级的 PC 值本来就不会发生任何变化,所以我们不需要对 NPC 模块进行改动。不过在之后涉及到清除 D 级指令时,我们就需要格外注意这个问题了!
接下来,我们还需要保证 D 级的所有数据不变。和 PC 模块相同,我们只需要为 FDreg 流水线寄存器加入写使能 en ,出现阻塞信号时关闭写使能即可。
然后是为 E 级注入空泡 nop 指令。如果像之前一样为 DEreg 流水线寄存器关闭写使能,这种做法肯定是行不通的,因为此时 E 级指令就会像 D 级指令一样留存在 E 级中。此时 DEreg 流水线寄存器真正需要的,是一个新的清除信号 clear ,当出现阻塞信号时,清除信号 clear 开启,将 DEreg 寄存器中的所有数据全部清空,这样就相当于在 E 级注入了一个新的 nop 指令。
最后是 M 级和 W 级,我们不需要对 EMreg 和 MWreg 两个流水线寄存器做任何更改,让 E 级和 M 级的指令自然流水到下一级即可。
到目前为止,我们终于学完了所有的五级流水线改造,从最基本的结构改造,到寄存器冲突的处理,我们的思维已经走了很远很远。现在是时候运用我们掌握的理论,开始用 Verilog 语言动手实践了!
5.4 使用 Verilog 模拟五级流水线 CPU
在上一节,我们通过简化的 Logisim 电路图,了解了将单周期 CPU 改造成五级流水线 CPU 的设计思路。在这一节,我们就来动手操作,在 Verilog 中实现这个精妙的系统!
首先,我们来实现 FDreg 、DEreg 、EMreg 、MWreg 这四个流水线寄存器,它们的具体实现思路非常简单,不过千万不要大意,一定要将需要流水的所有端口写全,具体可以参照这张完全体的电路图中流水线寄存器两侧的端口:
另外,我们不要忘了阻塞对流水线寄存器的影响,所以我们需要为相应的寄存器加入写使能信号 en 和清空信号 clear(为了增强拓展性,这里将所有的流水线寄存器都加上了这两个信号,虽然在目前的实现中有些信号完全不会发生改变):
1 | module FDreg( |
1 | module DEreg( |
1 | module EMreg( |
1 | module MWreg( |
同样,我们也需要为 PC 模块加入使能信号 en :
1 | module PC( |
接下来,我们对 NPC 模块的计算逻辑进行修改:
1 | module NPC( |
再接下来,我们将 ALU 模块中 zero 的判断正式移交给 CMP 模块,实现跳转判断的前移:
1 | module ALU( |
1 | module CMP( |
下一步就是对 Controller 模块的改造了!虽然我们确定了采取 D 级、E 级、M 级、W 级各一个 Controller 模块的策略,但同一种策略也有很多种不同的写法。在这里我们选取一种最便于上机加指令的写法,即 DController 、EController 、MController 、WController 全部引用同一个 Controller ,模块接口和内部结构完全相同,由主模块实现 $t_{rsuse}$ 、$t_{rtuse}$ 和 $t_{new}$ 的计算:
1 | module Controller( |
最后,我们来对主模块进行大刀阔斧的修改!首先,我们将主模块中的所有导线按流水线级进行拆分:
1 | module mips( |
接下来引入转发与阻塞相关的信号:
1 | module mips( |
接下来导入所有模块:
1 | module mips( |
接下来是一些 wire 型变量的赋值:
1 | module mips( |
最后就是激动人心的转发与阻塞部分了:
1 | module mips( |
终于终于终于!我们在 Verilog 上完成了五级流水线 CPU 的改造!这一次的任务真的说不上很轻松了,还是要稍微休息一下 —— 不过这次要记得回来,因为我们在下一节还要做一些练习,帮助你通过上机实验!
5.5 五级流水线 CPU 实战:加指令练习
这应该是本书中第一次正式拿出整整一节的篇幅讲解上机实验相关内容。大概是因为 P5 和 P6 的上机实验确实非常困难,没有事先的准备几乎一定无法通过,如果没有掌握技巧的话可能会一路挂到底。—— 挂了两回 P5 的 Kamonto 如此说道。
本节中出现的所有指令,有些是 MIPS 指令集里面真实存在的指令,有些是仿照往年助教清奇的思路虚构出来的指令。这些指令都仅用于本节中的练习,不会在后续的 CPU 中再次出现。
【计算类指令:slt】
首先,我们来从一个最简单的计算类指令 slt 开始练习,这是一个存在于 MIPS 指令集中的指令,下面是它的符号语言描述:
if GPR[rs] < GPR[rt] then
GPR[rd] ← 031 || 1
else
GPR[rd]← 032
endif